第1章 初识Flask
Flask介绍
搭建开发环境,编写一个最小的Flask程序并运行它,了解 Flask基本知识
这一切开始于2010年4月1日,Armin Ronacher在网上发布了一篇关 于“下一代Python微框架”的介绍文章,文章里称这个Denied框架不依赖 Python标准库,只需要复制一份deny.py放到你的项目文件夹就可以开始 编程。伴随着一本正经的介绍、名人推荐语、示例代码和演示视频,这 个“虚假”的项目让不少人都信以为真。
5天后, Flask就从这么一个愚人节玩笑诞生了。
Flask是使用Python编写的Web微框架。Web框架可以让我们不用关 心底层的请求响应处理,更方便高效地编写Web程序。因为Flask核心简 单且易于扩展,所以被称作微框架(micro framework)。Flask有两个主 要依赖,一个是WSGI(Web Server Gateway Interface,Web服务器网关 接口)工具集——Werkzeug,另一个是 Jinja2模板引擎。Flask只保留了Web开发的核 心功能,其他的功能都由外部扩展来实现,比如数据库集成、表单认 证、文件上传等。如果没有合适的扩展,你甚至可以自己动手开发。 Flask不会替你做决定,也不会限制你的选择。总之,Flask可以变成任 何你想要的东西,一切都由你做主。
Flask(瓶子,烧瓶)的命名据说是对另一个Python Web框架—— Bottle的双关语/调侃,即另一种容器(另一个Python Web框架)。 Werkzeug是德语单词“工具(tool)”,而Jinja指日本神社,因为神社 (庙)的英文temple与template(模板)相近而得名。
WSGI(Web Server Gateway Interface)是Python中用来规定Web服 务器如何与Python Web程序进行沟通的标准,在本书的第三部分将进行 详细介绍。
Flask与MVC架构
你也许会困惑为什么用来处理请求并生成响应的函数被称为“视图 函数(view function)”,其实这个命名并不合理。在Flask中,这个命名 的约定来自Werkzeug,而Werkzeug中URL匹配的实现主要参考了 Routes(一个URL匹配库),再往前追溯,Routes的实现又参考了Ruby on Rails。在Ruby on Rails中,术语views用来 表示MVC(Model-View-Controller,模型-视图-控制器)架构中的 View。
MVC架构最初是用来设计桌面程序的,后来也被用于Web程序,应 用了这种架构的Web框架有Django、Ruby on Rails等。在MVC架构中, 程序被分为三个组件:数据处理(Model)、用户界面(View)、交互 逻辑(Controller)。如果套用MVC架构的内容,那么Flask中视图函数 的名称其实并不严谨,使用控制器函数(Controller Function)似乎更合 适些,虽然它也附带处理用户界面。严格来说,Flask并不是MVC架构 的框架,因为它没有内置数据模型支持。为了方便表述,在本书中,使 用了app.route()装饰器的函数仍被称为视图函数,同时会使用“<函数 名>视图”(比如index视图)的形式来代指某个视图函数。
粗略归类,如果想要使用Flask来编写一个MVC架构的程序,那么 视图函数可以作为控制器(Controller),视图(View)则是我们将要介绍的使用Jinja2渲染的HTML模板,而模型(Model)可以使用其 他库来实现,在后面我们会介绍使用SQLAlchemy来创建数据库模型。
本章小结
Flask 基础其实很简单,这次主要是复习之前的知识,基础就不过多介绍了。
本章我们学习了Flask程序的运作方式和一些基本概念,这为我们进 一步学习打下了基础。
下面,我们会了解隐藏在Flask背后的重要角色 ——HTTP,并学习Flask是如何与之进行交互的。
第2章 Flask与HTTP
HTTP(Hypertext Transfer Protocol,超文本传输协议)定义了服务器和 客户端之间信息交流的格式和传递方式,它是万维网(World Wide Web)中数据交换的基础。
请求响应循环
为了更贴近现实,我们以一个真实的URL为例:
当我们在浏览器中的地址栏中输入这个URL,然后按下Enter时,稍等片刻,浏览器会显示一个问候页面。
这背后到底发生了什么?你一定 可以猜想到,这背后也有一个web程序运行着。
它负责接收用户的请求,并把对应的内容返回给客户端,显示在用户的浏览 器上。
事实上,每一个Web应用都包含这种处理模式,即“请求-响应循 环(Request-Response Cycle)”:
客户端发出请求,服务器端处理请求 并返回响应,如图所示。
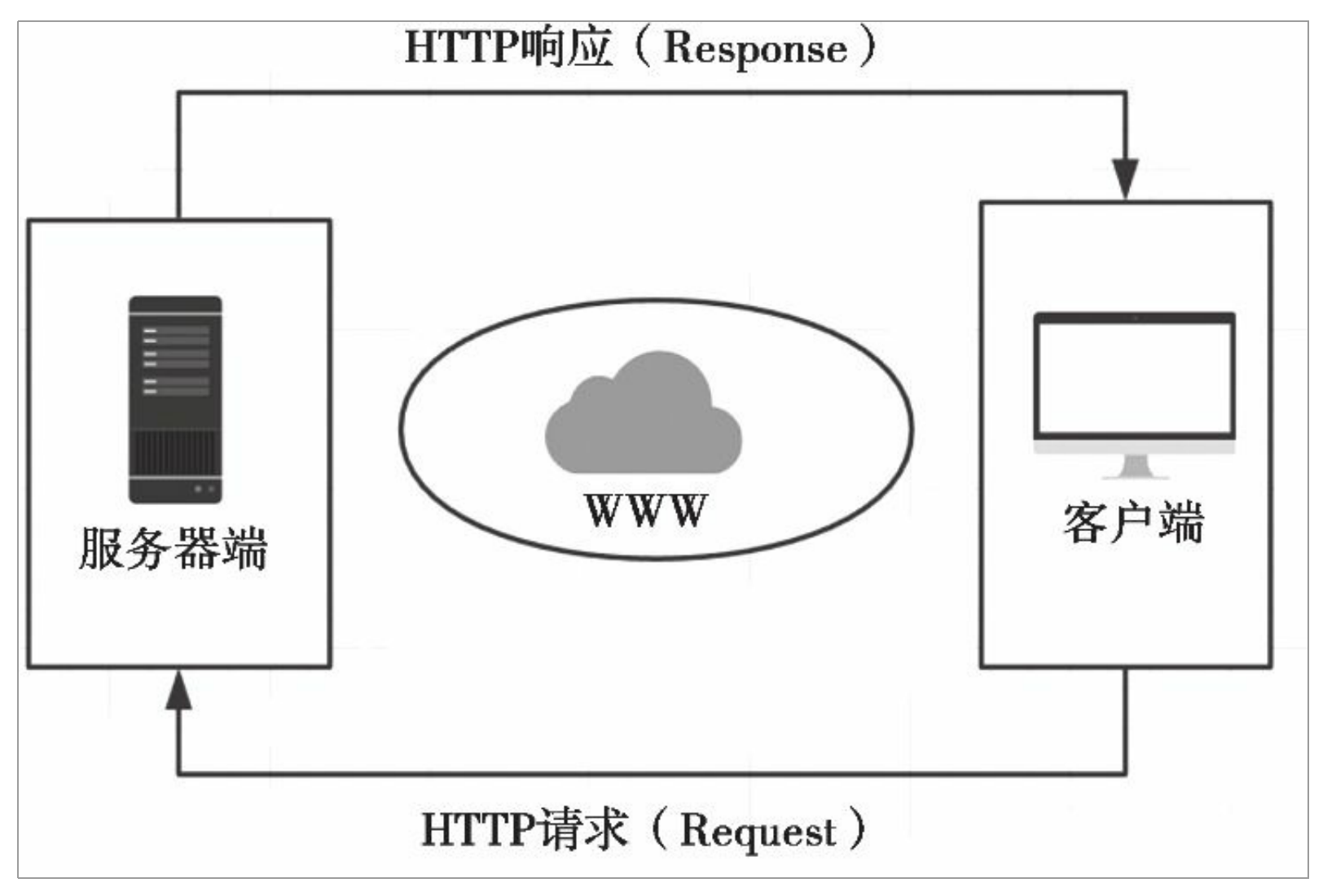
这是每一个Web程序的基本工作模式,如果再进一步,这个模式又 包含着更多的工作单元,下图展示了一个Flask程序工作的实际流程。
从下图中可以看出,HTTP在整个流程中起到了至关重要的作用, 它是客户端和服务器端之间沟通的桥梁。
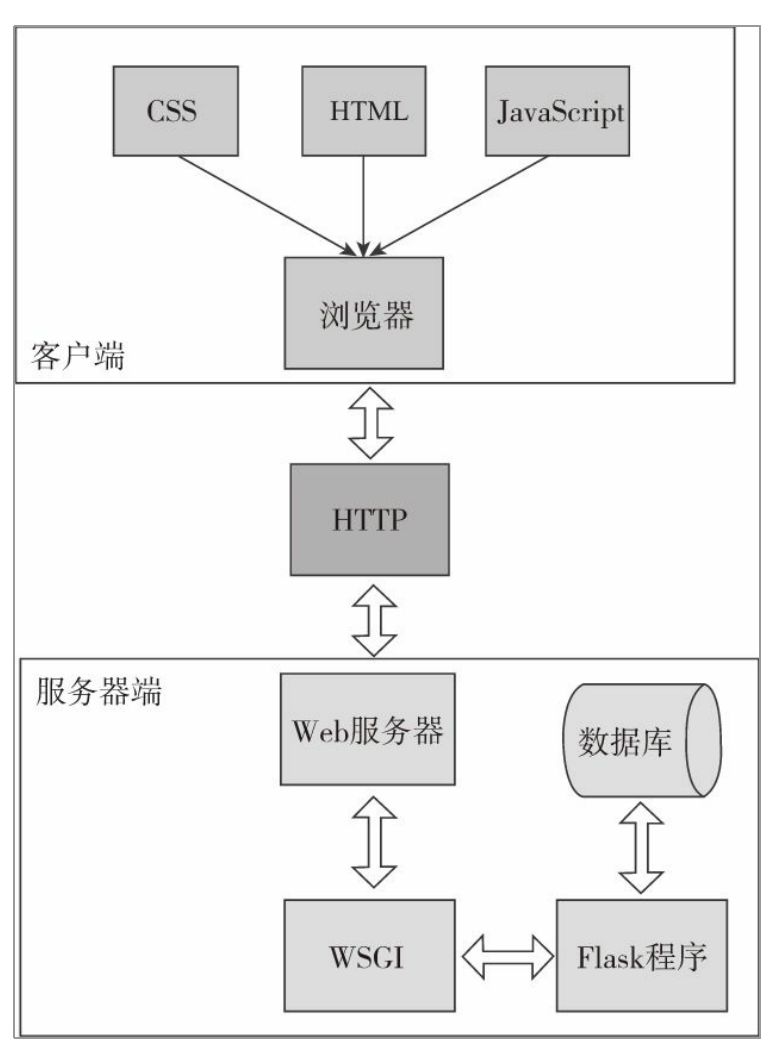
当用户访问一个URL,浏览器便生成对应的HTTP请求,经由互联 网发送到对应的Web服务器。
Web服务器接收请求,通过WSGI将HTTP 格式的请求数据转换成我们的Flask程序能够使用的Python数据。
在程序中,Flask根据请求的URL执行对应的视图函数,获取返回值生成响应。
响应依次经过WSGI转换生成HTTP响应,再经由Web服务器传递,最终 被发出请求的客户端接收。
浏览器渲染响应中包含的HTML和CSS代 码,并执行JavaScript代码,最终把解析后的页面呈现在用户浏览器的窗口中。
HTTP请求
URL是一个请求的起源。不论服务器是运行在美国洛杉矶,还是运 行在我们自己的电脑上,当我们输入指向服务器所在地址的URL,都会 向服务器发送一个HTTP请求。一个标准的URL由很多部分组成,以下面这个URL为例:
当我们在浏览器中访问这个URL时,随之产生的是一个发向http://helloflask.com所在服务器的请求。
请求的实质是发送到服务器 上的一些数据,这种浏览器与服务器之间交互的数据被称为报文(message),请求时浏览器发送的数据被称为请求报文(request message),而服务器返回的数据被称为响应报文(response message)。
请求报文
请求报文由请求的方法、URL、协议版本、首部字段(header)以及内容实体组成。
报文由报文首部和报文主体组成,两者由空行分隔,请求报文的主 体一般为空。
如果URL中包含查询字符串,或是提交了表单,那么报文 主体将会是查询字符串和表单数据。
报文首部包含了请求的各种信息和设置,比如客户端的类型、是否 设置缓存、语言偏好等。

Request对象
现在该让Flask的请求对象request出场了,这个请求对象封装了从客 户端发来的请求报文,我们能从它获取请求报文中的所有数据。
请求解析和响应封装实际上大部分是由Werkzeug完成的,Flask子 类化Werkzeug的请求(Request)和响应(Response)对象并添加了和程 序相关的特定功能。
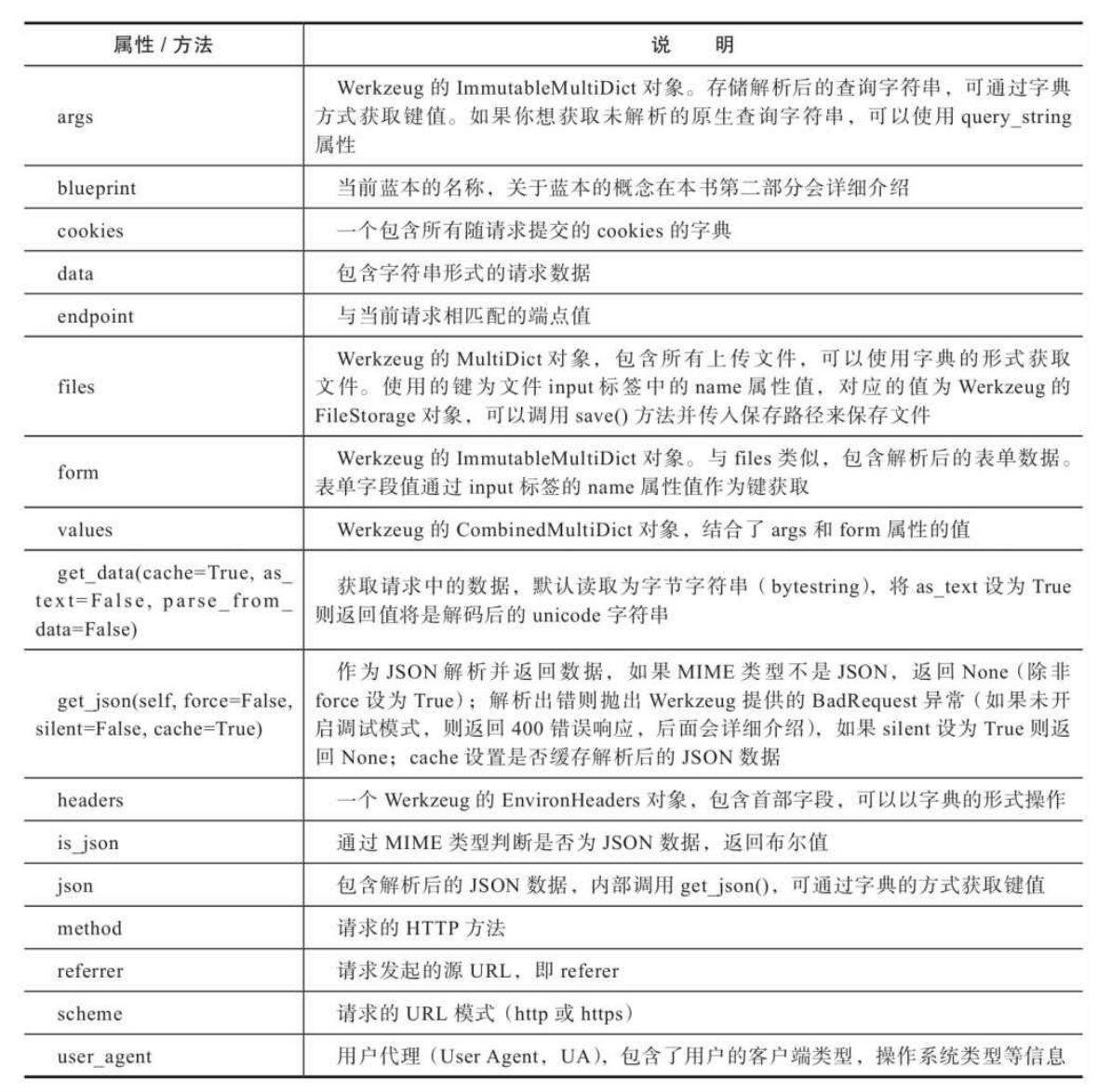
当Flask接收到请求后,请求对 象会提供多个属性来获取URL的各个部分,常用的属性如下表所示。
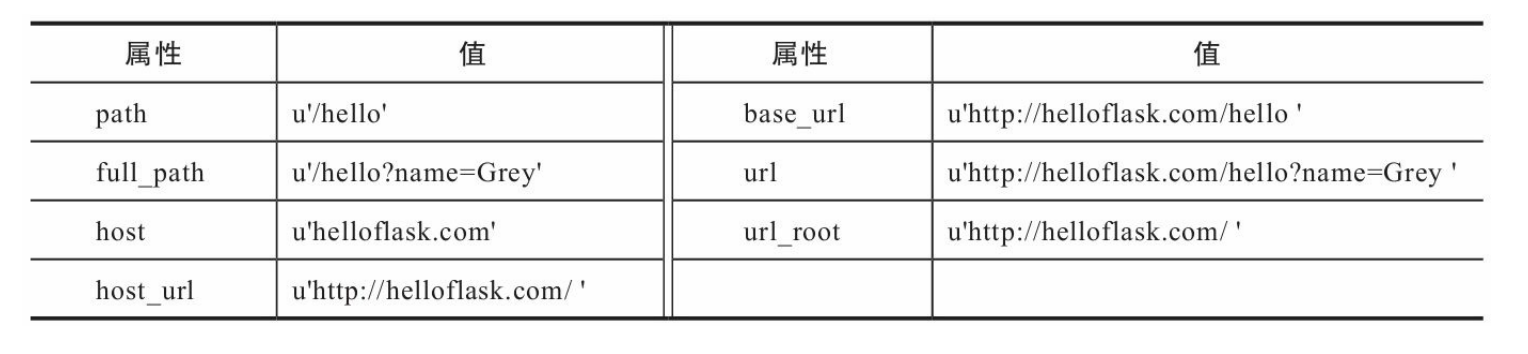
除了URL,请求报文中的其他信息都可以通过request对象提供的属性和方法获取。
在Flask中处理请求
URL是指向网络上资源的地址。在Flask中,我们需要让请求的URL 匹配对应的视图函数,视图函数返回值就是URL对应的资源。
- 路由匹配
为了便于将请求分发到对应的视图函数,程序实例中存储了一个路由表(app.url_map),其中定义了URL规则和视图函数的映射关系。
当请求发来后,Flask会根据请求报文中的URL(path部分)来尝试与这个 表中的所有URL规则进行匹配,调用匹配成功的视图函数。
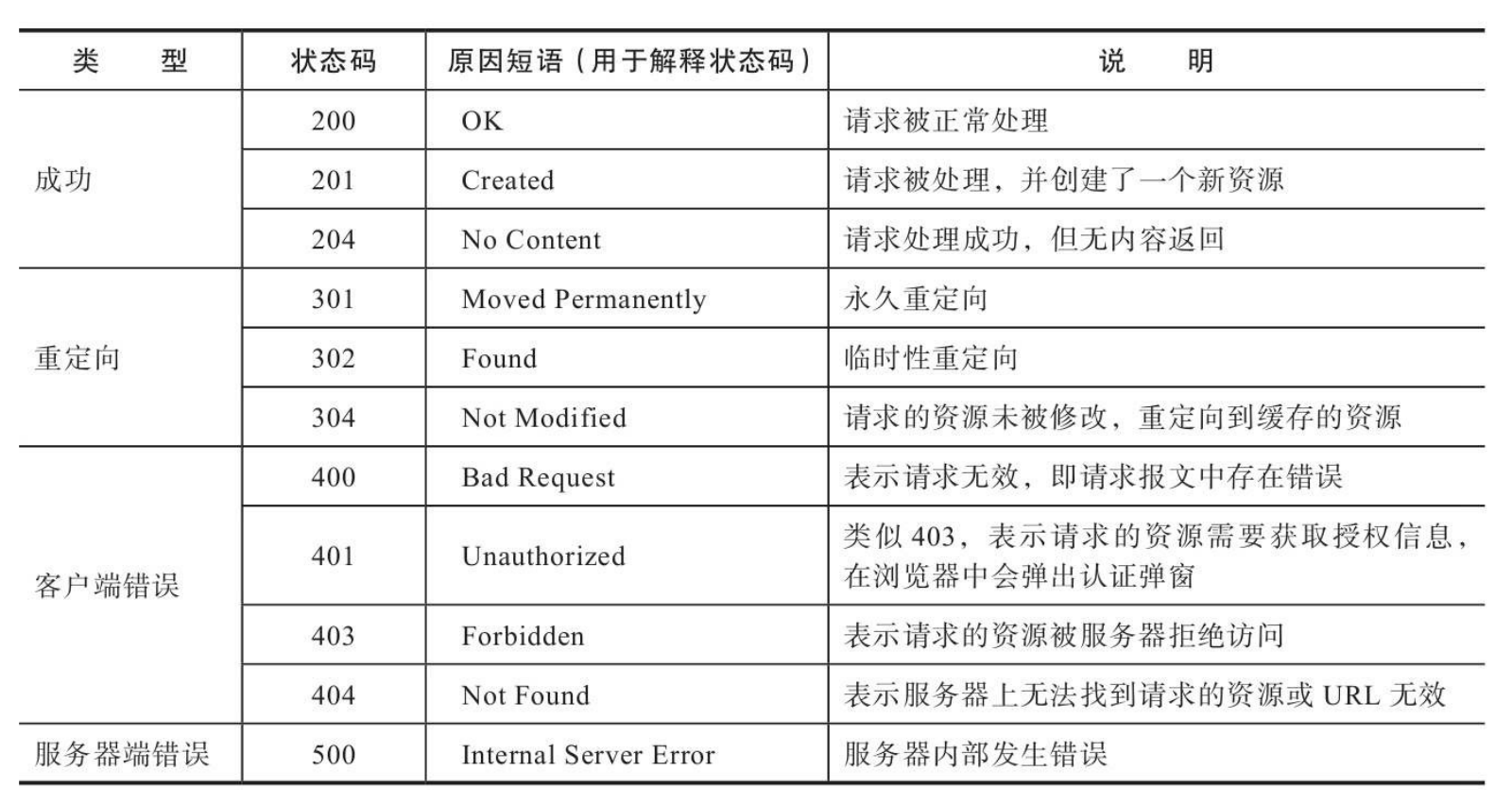
如果没有找到匹配的URL规则,说明程序中没有处理这个URL的视图函数,Flask会 自动返回404错误响应(Not Found,表示资源未找到)。
你可以尝试在 浏览器中访问http://localhost:5000/nothing ,因为我们的程序中没有视图 函数负责处理这个URL,所以你会得到404响应。 - 设置监听的HTTP方法
通过flask routes命令打印出的路由列表可以看到,每一个 路由除了包含URL规则外,还设置了监听的HTTP方法。
GET是最常用 的HTTP方法,所以视图函数默认监听的方法类型就是GET,HEAD、 OPTIONS方法的请求由Flask处理,而像DELETE、PUT等方法一般不会在程序中实现,在后面我们构建Web API时才会用到这些方法。
我们可以在app.route()装饰器中使用methods参数传入一个包含监 听的HTTP方法的可迭代对象。
比如,下面的视图函数同时监听GET请 求和POST请求:
1 |
|
当某个请求的方法不符合要求时,请求将无法被正常处理。比如, 在提交表单时通常使用POST方法,而如果提交的目标URL对应的视图 函数只允许GET方法,这时Flask会自动返回一个405错误响应(Method Not Allowed,表示请求方法不允许)。
3. URL处理
从前面的路由列表中可以看到,除了/hello,这个程序还包含许多 URL规则,比如和go_back端点对应的/goback/<int:year>。现在请尝试 访问http://localhost:5000/goback/34 ,在URL中加入一个数字作为时光倒 流的年数,你会发现加载后的页面中有通过传入的年数计算出的年 份:“Welcome to 1984!”。仔细观察一下,你会发现URL规则中的变量 部分有一些特别,<int:year>表示为year变量添加了一个int转换器, Flask在解析这个URL变量时会将其转换为整型。
1 |
|
请求钩子
有时我们需要对请求进行预处理(preprocessing)和后处理 (postprocessing),这时可以使用Flask提供的一些请求钩子 (Hook),它们可以用来注册在请求处理的不同阶段执行的处理函数 (或称为回调函数,即Callback)。这些请求钩子使用装饰器实现,通 过程序实例app调用,用法很简单:以before_request钩子(请求之前) 为例,当你对一个函数附加了app.before_request装饰器后,就会将这个 函数注册为before_request处理函数,每次执行请求前都会触发所有 before_request处理函数。
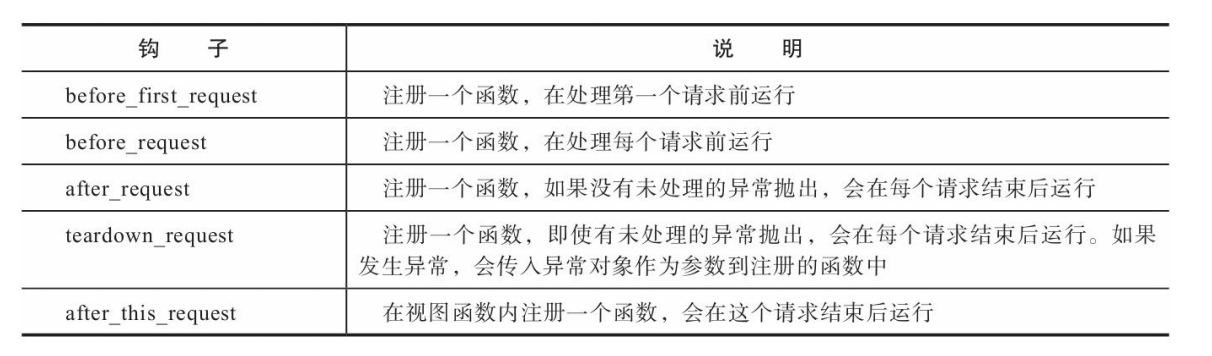
这些钩子使用起来和app.route()装饰器基本相同,每个钩子可以 注册任意多个处理函数,函数名并不是必须和钩子名称相同,下面是一 个基本示例:
假如我们创建了三个视图函数A、B、C,其中视图C使用了 after_this_request钩子,那么当请求A进入后,整个请求处理周期的请求 处理函数调用流程如图2-7所示。 下面是请求钩子的一些常见应用场景:
- before_first_request:
在玩具程序中,运行程序前我们需要进行一 些程序的初始化操作,比如创建数据库表,添加管理员用户。这些工作 可以放到使用before_first_request装饰器注册的函数中。 - before_request:
比如网站上要记录用户最后在线的时间,可以通 过用户最后发送的请求时间来实现。为了避免在每个视图函数都添加更 新在线时间的代码,我们可以仅在使用before_request钩子注册的函数中 调用这段代码。 - after_request:
我们经常在视图函数中进行数据库操作,比如更 新、插入等,之后需要将更改提交到数据库中。提交更改的代码就可以 放到after_request钩子注册的函数中。
另一种常见的应用是建立数据库连接,通常会有多个视图函数需要 建立和关闭数据库连接,这些操作基本相同。一个理想的解决方法是在 请求之前(before_request)建立连接,在请求之后(teardown_request) 关闭连接。通过在使用相应的请求钩子注册的函数中添加代码就可以实 现。这很像单元测试中的setUp()方法和tearDown()方法。
HTTP响应
在Flask程序中,客户端发出的请求触发相应的视图函数,获取返回 值会作为响应的主体,最后生成完整的响应,即响应报文。
响应报文
响应报文主要由协议版本、状态码(status code)、原因短语 (reason phrase)、响应首部和响应主体组成。
以发向localhost:5000/hello的请求为例,服务器生成的响应报文示意如下表所示。
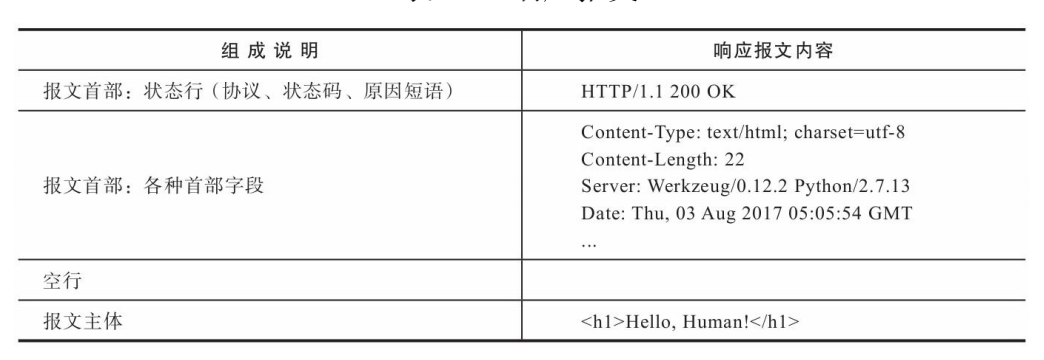
响应报文的首部包含一些关于响应和服务器的信息,这些内容由 Flask生成,而我们在视图函数中返回的内容即为响应报文中的主体内容。
浏览器接收到响应后,会把返回的响应主体解析并显示在浏览器窗口上。
HTTP状态码用来表示请求处理的结果,表2-9是常见的几种状态码 和相应的原因短语。
在Flask中生成响应
响应在Flask中使用Response对象表示,响应报文中的大部分内容由 服务器处理,大多数情况下,我们只负责返回主体内容。
根据我们在上一节介绍的内容,Flask会先判断是否可以找到与请求 URL相匹配的路由,如果没有则返回404响应。
如果找到,则调用对应 的视图函数,视图函数的返回值构成了响应报文的主体内容,正确返回 时状态码默认为200。
Flask会调用make_response()方法将视图函数返 回值转换为响应对象。
完整地说,视图函数可以返回最多由三个元素组成的元组:响应主 体、状态码、首部字段。其中首部字段可以为字典,或是两元素元组组成的列表。
比如,普通的响应可以只包含主体内容:
1 |
|
默认的状态码为200,下面指定了不同的状态码:
1 |
|
有时你会想附加或修改某个首部字段。比如,要生成状态码为3XX 的重定向响应,需要将首部中的Location字段设置为重定向的目标 URL:
1 |
|
现在访问http://localhost:5000/hello ,会重定向 到http://www.example.com 。在多数情况下,除了响应主体,其他部分我们通常只需要使用默认值即可。
- 重定向
在Web程序中,我们经常需要进行重定向。比如,当某个用户在没 有经过认证的情况下访问需要登录后才能访问的资源,程序通常会重定向到登录页面。
对于重定向这一类特殊响应,Flask提供了一些辅助函数。
除了像前面那样手动生成302响应,我们可以使用Flask提供的redirect()函数来生成重定向响应,重定向的目标URL作为第一个参数。
前面的例子可以简化为:
1 | from flask import Flask, redirect |
使用redirect()函数时,默认的状态码为302,即临时重定向。如果你想修改状态码,可以在redirect()函数中作为第二个参数或使用code关键字传入。
如果要在程序内重定向到其他视图,那么只需在redirect()函数中
使用url_for()函数生成目标URL即可
1 | from flask import Flask, redirect, url_for |
- 错误响应
大多数情况下,Flask会自动处理常见的错误响应。HTTP错误对应的异常类在Werkzeug的werkzeug.exceptions模块中定义,抛出这些异常即可返回对应的错误响应。
如果你想手动返回错误响应,更方便的方法 是使用Flask提供的abort()函数。 在abort()函数中传入状态码即可返回对应的错误响应
1 | from flask import Flask, abort |
响应格式
在HTTP响应中,数据可以通过多种格式传输。大多数情况下,我 们会使用HTML格式,这也是Flask中的默认设置。在特定的情况下,我 们也会使用其他格式。
MIME类型(又称为media type或content type)是一种用来标识文件 类型的机制,它与文件扩展名相对应,可以让客户端区分不同的内容类型,并执行不同的操作。一般的格式为“类型名/子类型名”,其中的子类 型名一般为文件扩展名。
比如,HTML的MIME类型为“text/html”,png图片的MIME类型为“image/png”。完整的标准MIME类型列表可以在这 里看到:https://www.iana.org/assignments/media-types/media-types.xhtml。
如果你想使用其他MIME类型,可以通过Flask提供的 make_response()方法生成响应对象,传入响应的主体作为参数,然后 使用响应对象的mimetype属性设置MIME类型
1 | from flask import make_response |
你也可以直接设置首部字段,比如response.headers['Content-Type']='text/xml;charset=utf-8'。但操作mimetype属性更加方便,而且不用设置字符集(charset)选项。
常用的数据格式有纯文本、HTML、XML和JSON,下面我们分别 对这几种数据进行简单的介绍和分析。
- 纯文本
MIME类型:text/plain
事实上,其他几种格式本质上都是纯文本。比如同样是一行包含 HTML标签的文本<h1>Hello,Flask!</h1>,当MIME类型设置为纯 文本时,浏览器会以文本形式显示<h1>Hello,Flask!</h1>;当 MIME类型声明为text/html时,浏览器则会将其作为标题1样式的HTML 代码渲染。 - HTML
MIME类型:text/html
HTML指Hypertext Markup Language(超文本标记语言),是最常用的数据格式,也是Flask返回响 应的默认数据类型。从我们在本书一开始的最小程序中的视图函数返回 的字符串,到我们后面会学习的HTML模板,都是HTML。当数据类型 为HTML时,浏览器会自动根据HTML标签以及样式类定义渲染对应的 样式。
因为HTML常常包含丰富的信息,我们可以直接将HTML嵌入页面 中,处理起来比较方便。因此,在普通的HTTP请求中我们使用HTTP作 为响应的内容,这也是默认的数据类型。 - XML
MIME类型:application/xml
XML指Extensible Markup Language(可扩展标记语言),它是一种简单灵活的文本格式,被设计 用来存储和交换数据。XML的出现主要就是为了弥补HTML的不足:对 于仅仅需要数据的请求来说,HTML提供的信息太过丰富了,而且不易 于重用。XML和HTML一样都是标记性语言,使用标签来定义文本,但 HTML中的标签用于显示内容,而XML中的标签只用于定义数据。 XML一般作为AJAX请求的响应格式,或是Web API的响应格式。 - JSON
MIME类型:application/json
JSON指JavaScript Object Notation(JavaScript对 象表示法),是一种流行的、轻量的数据交换格式。它的出现又弥补了 XML的诸多不足:XML有较高的重用性,但XML相对于其他文档格式 来说体积稍大,处理和解析的速度较慢。JSON轻量,简洁,容易阅读 和解析,而且能和Web默认的客户端语言JavaScript更好地兼容。JSON 的结构基于“键值对的集合”和“有序的值列表”,这两种数据结构类似 Python中的字典(dictionary)和列表(list)。正是因为这种通用的数据 结构,使得JSON在同样基于这些结构的编程语言之间交换成为可能。
来一块Cookie
HTTP是无状态(stateless)协议。也就是说,在一次请求响应结束后,服务器不会留下任何关于对方状态的信息。
但是对于某些Web程序来说,客户端的某些信息又必须被记住,比如用户的登录状态,这样才可以根据用户的状态来返回不同的响应。
为了解决这类问题,就有了Cookie技术。Cookie技术通过在请求和响应报文中添加Cookie数据来保 存客户端的状态信息。
在Flask中,如果想要在响应中添加一个cookie,最方便的方法是使 用Response类提供的set_cookie()方法。要使用这个方法,我们需要先 使用make_response()方法手动生成一个响应对象,传入响应主体作为 参数。这个响应对象默认实例化内置的Response类。
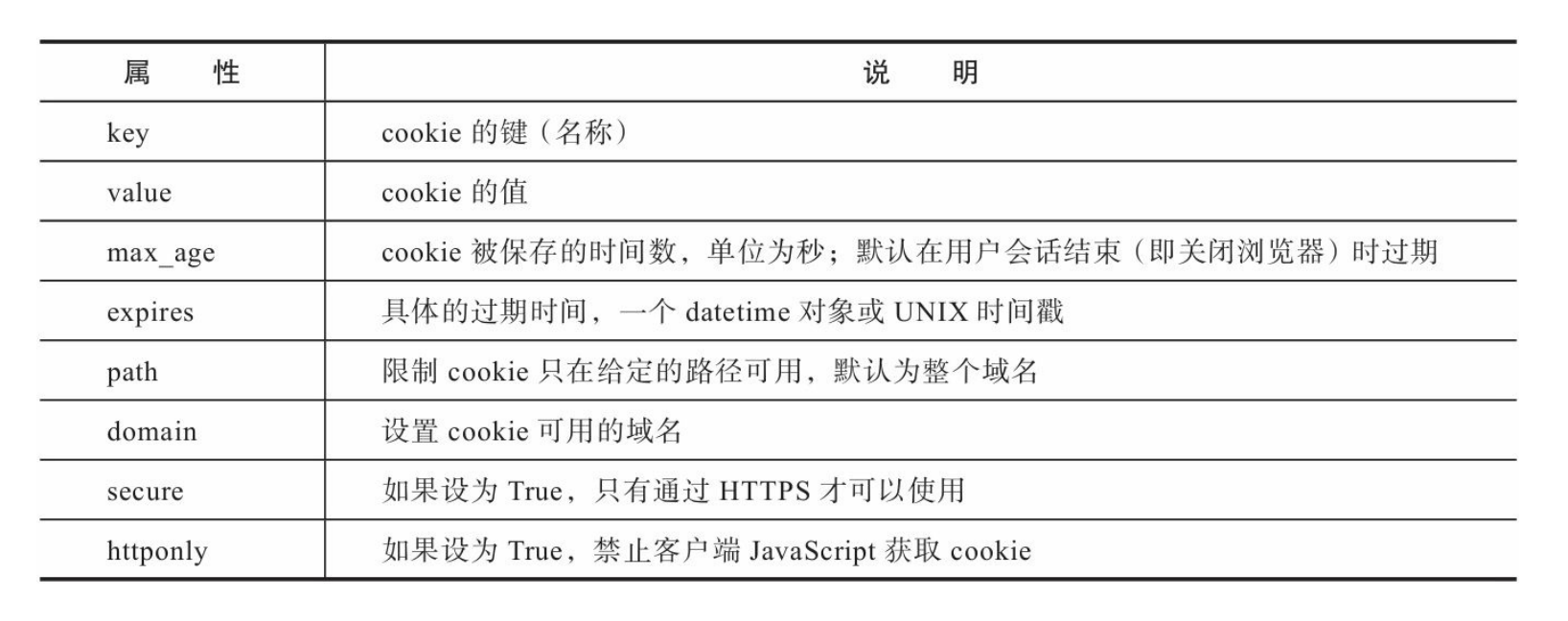
set_cookie视图用来设置cookie,它会将URL中的name变量的值设置 到名为name的cookie里
1 | from flask import Flask, make_response, url_for |
当浏览器保存了服务器端设置的Cookie后,浏览器再次发送到该服 务器的请求会自动携带设置的Cookie信息,Cookie的内容存储在请求首部的Cookie字段中,整个交互过程由上到下如下图所示。
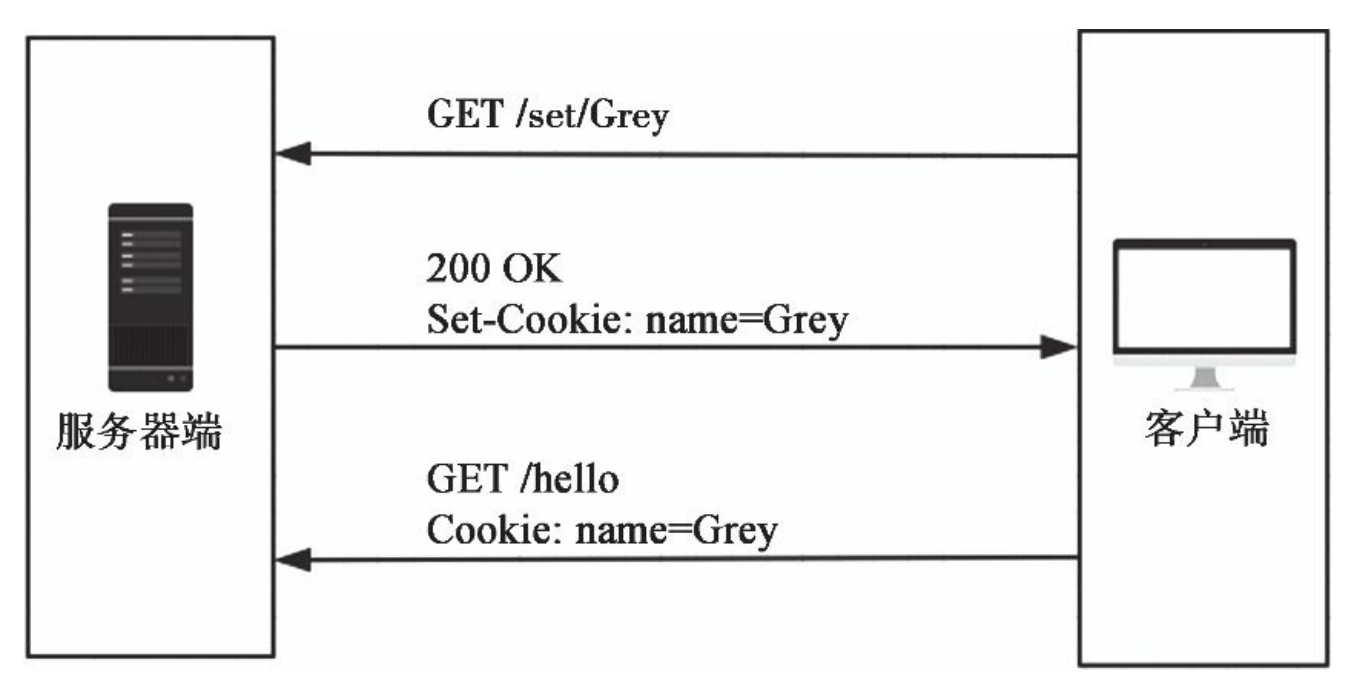
在Flask中,Cookie可以通过请求对象的cookies属性读取。在修改后 的hello视图中,如果没有从查询参数中获取到name的值,就从Cookie中寻找:
1 | from flask import Flask, request |
session:安全的Cookie
Cookie在Web程序中发挥了很大的作用,其中最重要的功能是存储 用户的认证信息。我们先来看看基于浏览器的用户认证是如何实现的。
当我们使用浏览器登录某个社交网站时,会在登录表单中填写用户名和 密码,单击登录按钮后,这会向服务器发送一个包含认证数据的请求。
服务器接收请求后会查找对应的账户,然后验证密码是否匹配,如果匹 配,就在返回的响应中设置一个cookie,比如,login_user:greyli。
响应被浏览器接收后,cookie会被保存在浏览器中。当用户再次向 这个服务器发送请求时,根据请求附带的Cookie字段中的内容,服务器 上的程序就可以判断用户的认证状态,并识别出用户。
但是这会带来一个问题,在浏览器中手动添加和修改Cookie是很容 易的事,仅仅通过浏览器插件就可以实现。
所以,如果直接把认证信息 以明文的方式存储在Cookie里,那么恶意用户就可以通过伪造cookie的 内容来获得对网站的权限,冒用别人的账户。
为了避免这个问题,我们 需要对敏感的Cookie内容进行加密。方便的是,Flask提供了session对象 用来将Cookie数据加密储存。
- 设置程序密钥
session通过密钥对数据进行签名以加密数据,因此,我们得先设置 一个密钥。这里的密钥就是一个具有一定复杂度和随机性的字符串,比 如“Drmhze6EPcv0fN_81Bj-nA”。
程序的密钥可以通过Flask.secret_key属性或配置变量SECRET_KEY 设置,比如:
更安全的做法是把密钥写进系统环境变量(在命令行中使用export 或set命令),或是保存在.env文件中:
1 | app.secret_key = 'secret string' |
然后在程序脚本中使用os模块提供的getenv()方法获取:
1 | import os |
- 模拟用户认证
下面我们会使用session模拟用户的认证功能。代码清单2-5是用来 登入用户的login视图。
1 | from flask import redirect, session, url_for |
这个登录视图只是简化的示例,在实际的登录中,我们需要在页面 上提供登录表单,供用户填写账户和密码,然后在登录视图里验证账户和密码的有效性。
session对象可以像字典一样操作,我们向session中添 加一个logged-in cookie,将它的值设为True,表示用户已认证。
当我们使用session对象添加cookie时,数据会使用程序的密钥对其 进行签名,加密后的数据存储在一块名为session的cookie里。
Flask上下文
我们可以把编程中的上下文理解为当前环境(environment)的快照 (snapshot)。如果把一个Flask程序比作一条可怜的生活在鱼缸里的鱼 的话,那么它当然离不开身边的环境。
上下文全局变量
每一个视图函数都需要上下文信息,在前面我们学习过Flask将请求 报文封装在request对象中。按照一般的思路,如果我们要在视图函数中使用它,就得把它作为参数传入视图函数,就像我们接收URL变量一 样。但是这样一来就会导致大量的重复,而且增加了视图函数的复杂度。
在前面的示例中,我们并没有传递这个参数,而是直接从Flask导入 一个全局的request对象,然后在视图函数里直接调用request的属性获取数据。你一定好奇,我们在全局导入时request只是一个普通的Python对 象,为什么在处理请求时,视图函数里的request就会自动包含对应请求 的数据?这是因为Flask会在每个请求产生后自动激活当前请求的上下文,激活请求上下文后,request被临时设为全局可访问。而当每个请求结束后,Flask就销毁对应的请求上下文。
我们在前面说request是全局对象,但这里的“全局”并不是实际意义 上的全局。我们可以把这些变量理解为动态的全局变量。
在多线程服务器中,在同一时间可能会有多个请求在处理。假设有 三个客户端同时向服务器发送请求,这时每个请求都有各自不同的请求报文,所以请求对象也必然是不同的。
因此,请求对象只在各自的线程 内是全局的。Flask通过本地线程(thread local)技术将请求对象在特定 的线程和请求中全局可访问。具体内容和应用我们会在后面进行详细介绍。
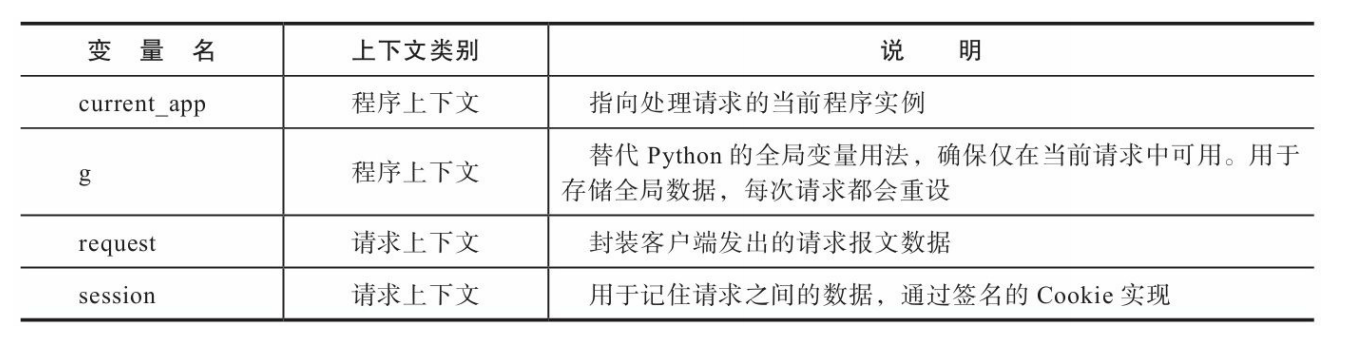
我们在前面对session和request都了解得差不多了,这里简单介绍一 下current_app和g。
你在这里也许会疑惑,既然有了程序实例app对象,为什么还需要 current_app变量。在不同的视图函数中,request对象都表示和视图函数 对应的请求,也就是当前请求(current request)。而程序也会有多个程 序实例的情况,为了能获取对应的程序实例,而不是固定的某一个程序实例,我们就需要使用current_app变量,后面会详细介绍。
因为g存储在程序上下文中,而程序上下文会随着每一个请求的进入而激活,随着每一个请求的处理完毕而销毁,所以每次请求都会重设 这个值。我们通常会使用它结合请求钩子来保存每个请求处理前所需要 的全局变量,比如当前登入的用户对象,数据库连接等。
在前面的示例中,我们在hello视图中从查询字符串获取name的值,如果每一个视图都需要这个值,那么就要在每个视图重复这行代码。借助g我们可以将这 个操作移动到before_request处理函数中执行,然后保存到g的任意属性上:
1 | from flask import g |
设置这个函数后,在其他视图中可以直接使用g.name获取对应的值。另外,g也支持使用类似字典的get()、pop()以及setdefault()方法进行操作。
激活上下文
阳光柔和,鱼儿在水里欢快地游动,这一切都是上下文存在后的美好景象。如果没有上下文,我们的程序只能直挺挺地躺在鱼缸里。
在下 面这些情况下,Flask会自动帮我们激活程序上下文:
- 当我们使用flask run命令启动程序时。
- 使用旧的app.run()方法启动程序时。
- 执行使用@app.cli.command()装饰器注册的flask命令时。
- 使用flask shell命令启动Python Shell时。
当请求进入时,Flask会自动激活请求上下文,这时我们可以使用request和session变量。
另外,当请求上下文被激活时,程序上下文也被自动激活。当请求处理完毕后,请求上下文和程序上下文也会自动销毁。
也就是说,在请求处理时这两者拥有相同的生命周期。
结合Python的代码执行机制理解,这也就意味着,我们可以在视图 函数中或在视图函数内调用的函数/方法中使用所有上下文全局变量。
在使用flask shell命令打开的Python Shell中,或是自定义的flask命令函数 中,我们可以使用current_app和g变量,也可以手动激活请求上下文来使用request和session。
如果我们在没有激活相关上下文时使用这些变量,Flask就会抛出 RuntimeError异常:RuntimeError:Working outside of application context.或是RuntimeError:Working outside of request context.。
上下文钩子
在前面我们学习了请求生命周期中可以使用的几种钩子,Flask也为上下文提供了一个teardown_appcontext钩子,使用它注册的回调函数会 在程序上下文被销毁时调用,而且通常也会在请求上下文被销毁时调用。
比如,你需要在每个请求处理结束后销毁数据库连接:
1 |
|
使用app.teardown_appcontext装饰器注册的回调函数需要接收异常 对象作为参数,当请求被正常处理时这个参数值将是None,这个函数的 返回值将被忽略。
上下文是Flask的重要话题,在这里我们也只是简单了解一下,后面我们会详细了解上下文的实现原理。
HTTP进阶实践
重定向回上一个页面
在前面的示例程序中,我们使用redirect()函数生成重定向响应。 比如,在login视图中,登入用户后我们将用户重定向到/hello页面。在 复杂的应用场景下,我们需要在用户访问某个URL后重定向到上一个页 面。最常见的情况是,用户单击某个需要登录才能访问的链接,这时程 序会重定向到登录页面,当用户登录后合理的行为是重定向到用户登录 前浏览的页面,以便用户执行未完成的操作,而不是直接重定向到主页。在示例程序中,我们创建了两个视图函数foo和bar,分别显示一个 Foo页面和一个Bar页面。
1 |
|
- 获取上一个页面的URL
要重定向回上一个页面,最关键的是获取上一个页面的URL。上一 个页面的URL一般可以通过两种方式获取:
- (1)HTTP referer
HTTP referer(起源为referrer在HTTP规范中的错误拼写)是一个用来记录请求发源地址的HTTP首部字段(HTTP_REFERER),即访问来源。
当用户在某个站点单击链接,浏览器向新链接所在的服务器发起请求,请求的数据中包含的HTTP_REFERER字段记录了用户所在的原站点URL。
这个值通常会用来追踪用户,比如记录用户进入程序的外部站点,以此来更有针对性地进行营销。在Flask中,referer的值可以通过请求对象的referrer属性获取,即request.referrer(正确拼写形式)。
1 | return redirect(request.referrer) |
- (2)查询参数
除了自动从referrer获取,另一种更常见的方式是在URL中手动加入包含当前页面URL的查询参数,这个查询参数一般命名为next。比如,下面在foo和bar视图的返回值中的URL后添加next参数
1 | from flask import request |
- 对URL进行安全验证
虽然我们已经实现了重定向回上一个页面的功能,但安全问题不容 小觑,鉴于referer和next容易被篡改的特性,如果我们不对这些值进行 验证,则会形成开放重定向(Open Redirect)漏洞。
以URL中的next参数为例,next变量以查询字符串的方式写在URL里,因此任何人都可以发给某个用户一个包含next变量指向任何站点的链接。举个简单的例子,如果你访问下面的URL:
1 | http://localhost:5000/do-something?next=http://helloflask.com |
程序会被重定向到http://helloflask.com 。也就是说,如果我们不验 证next变量指向的URL地址是否属于我们的应用内,那么程序很容易就 会被重定向到外部地址。
假设我们的应用是一个银行业务系统(下面简称网站A),某个攻击者模仿我们的网站外观做了一个几乎一模一样的网站(下面简称网站 B)。
接着,攻击者伪造了一封电子邮件,告诉用户网站A账户信息需要更新,然后向用户提供一个指向网站A登录页面的链接,但链接中包 含一个重定向到网站B的next变量,比如:http://exampleA.com/login?next=http://maliciousB.com。
当用户在A网站登录后,如果A网站重定向到next对应的URL,那么就会导致重定向到攻击者编写的B网站。因为B网站完全模仿A网站的外观,攻击者就可以在重定向后的B网站诱导用户输入敏感信息,比如银行卡号及密码。
确保URL安全的关键就是判断URL是否属于程序内部,我们创建了一个URL验证函数is_safe_url(),用来验证next变 量值是否属于程序内部URL。
1 | from urlparse import urlparse, urljoin |
使用AJAX技术发送异步请求
在传统的Web应用中,程序的操作都是基于请求响应循环来实现的。每当页面状态需要变动,或是需要更新数据时,都伴随着一个发向服务器的请求。
当服务器返回响应时,整个页面会重载,并渲染新页面。
这种模式会带来一些问题。首先,频繁更新页面会牺牲性能,浪费 服务器资源,同时降低用户体验。
另外,对于一些操作性很强的程序来说,重载页面会显得很不合理。比如我们做了一个Web计算器程序,所有的按钮和显示屏幕都很逼真,但当我们单击“等于”按钮时,要等到页面重新加载后才在显示屏幕上看到结果,这显然会严重影响用户体验。
我们这一节要学习的AJAX技术可以完美地解决这些问题。
HTTP服务器端推送
不论是传统的HTTP请求-响应式的通信模式,还是异步的AJAX式请求,服务器端始终处于被动的应答状态,只有在客户端发出请求的情况下,服务器端才会返回响应。这种通信模式被称为客户端拉取 (client pull)。在这种模式下,用户只能通过刷新页面或主动单击加载 按钮来拉取新数据。
然而,在某些场景下,我们需要的通信模式是服务器端的主动推送 (server push)。比如,一个聊天室有很多个用户,当某个用户发送消息后,服务器接收到这个请求,然后把消息推送给聊天室的所有用户。 类似这种关注实时性的情况还有很多,比如社交网站在导航栏实时显示新提醒和私信的数量,用户的在线状态更新,股价行情监控、显示商品 库存信息、多人游戏、文档协作等。
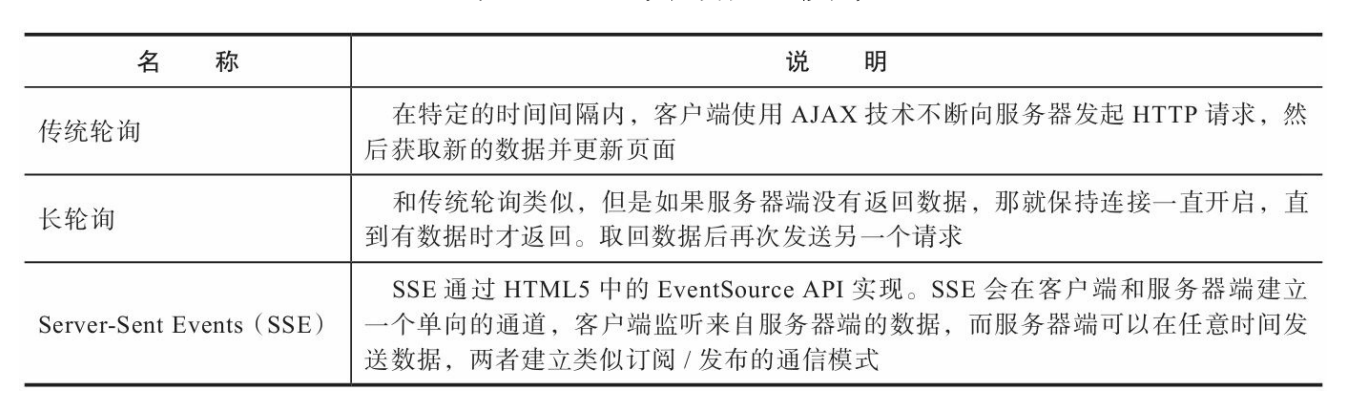
Web安全防范
无论是简单的博客,还是大型的社交网站,Web安全都应该放在首位。Web安全问题涉及广泛,我们在这里介绍其中常见的几种攻击(attack)和其他常见的漏洞(vulnerability)。
对于Web程序的安全问题,一个首要的原则是:永远不要相信你的用户。大部分Web安全问题都是因为没有对用户输入的内容进行“消 毒”造成的。
注入攻击
在OWASP(Open Web Application Security Project,开放式Web程 序安全项目)发布的最危险的Web程序安全风险Top 10中,无论是最新 的2017年的排名,2013年的排名还是最早的2010年,注入攻击 (Injection)都位列第一。
注入攻击包括系统命令(OS Command)注 入、SQL(Structured Query Language,结构化查询语言)注入(SQL Injection)、NoSQL注入、ORM(Object Relational Mapper,对象关系 映射)注入等。我们这里重点介绍的是SQL注入。XSS攻击
XSS(Cross-Site Scripting,跨站脚本)攻击历史悠久,最远可以追溯到90年代,但至今仍然是危害范围非常广的攻击方式。在OWASP TOP 10中排名第7。CSRF攻击
CSRF(Cross Site Request Forgery,跨站请求伪造)是一种近年来才逐渐被大众了解的网络攻击方式,又被称为One-Click Attack或Session Riding。在OWASP上一次(2013)的TOP 10 Web程序安全风险中,它位列第8。随着大部分程序的完善,各种框架都内置了对CSRF保护的支 持,但目前仍有5%的程序受到威胁。
本章小结
HTTP是各种Web程序的基础,本章只是简要介绍了和Flask相关的部分,没有涉及HTTP底层的TCP/IP或DNS协议。
建议你通过阅读相关 书籍来了解完整的Web原理,这将有助于编写更完善和安全的Web程序。
在下一章,我们会学习使用Flask的模板引擎——Jinja2,通过学习运用模板和静态文件,我们可以让程序变得更加丰富和完善。
现在前后端分离的架构下,Jinja2我们就简单的介绍一下。
Jinja模板
在动态Web程序中,视图函数返回的HTML数据往往需要根据相应的变量(比如查询参数)动态生成。
当HTML代码保存到单独的文件中时,我们没法再使用字符串格式化或拼接字符串的方式来在HTML代码中插入变量,这时我们需要使用模板引擎(template engine)。
借助模板引擎,我们可以在HTML文件中使用特殊的语法来标记出变量,这类包含固定内容和动态部分的可重用文件称为模板(template)。
模板引擎的作用就是读取并执行模板中的特殊语法标记,并根据传入的数据将变量替换为实际值,输出最终的HTML页面,这个过程被称为渲染(rendering)。
Flask默认使用的模板引擎是Jinja2,它是一个功 能齐全的Python模板引擎,除了设置变量,还允许我们在模板中添加if判断,执行for迭代,调用函数等,以各种方式控制模板的输出。
对于Jinja2来说,模板可以是任何格式的纯文本文件,比如HTML、XML、 CSV、LaTeX等。
模板基本用法
1 | user = { |
我们在templates目录下创建一个watchlist.html作为模板文件,然后 使用Jinja2支持的语法在模板中操作这些变量
1 |
|
Jinja2 的用法很多,其实和Java的那个jsp用法差不多,具体的用法可以查询文档
Jinja2 其实跟jsp的优缺点也很像,在复杂的页面并不太好用,还是用Web API和Vue比较适合我。
总结
上面的3章介绍的都是Flask的基础知识,比较简单也比较枯燥,主要的篇幅放在了HTTP上面,其他两章在官方的文档中介绍的很详细。
基础篇还剩一部分,将会在后面介绍,剩下的基础篇会结合基础知识和实际的用途,以及代码来介绍。




