前言
前面介绍了Flask和HTTP的基础知识,下面会介绍Flask的基础用法
第4章 表单
在Web程序中,表单是和用户交互最常见的方式之一。用户注册、登录、撰写文章、编辑设置,无一不用到表单。不过,表单的处理却并不简单。
你不仅要创建表单,验证用户输入的内容,向用户显示错误提示,还要获取并保存数据。幸运的是,强大的WTForms可以帮我们解决这些问题。WTForms是一个使用Python编写的表单库,它使得表单的定 义、验证(服务器端)和处理变得非常轻松。这一章我们会介绍在Web 程序中处理表单的方法和技巧。
使用Flask-WTF处理表单
扩展Flask-WTF集成了WTForms,使用它可以在Flask中更方便地使用WTForms。Flask-WTF将表单数据解析、CSRF保护、文件上传等功能与Flask集成,另外还附加了reCAPTCHA支持。
Flask-WTF默认为每个表单启用CSRF保护,它会为我们自动生成和 验证CSRF令牌。默认情况下,Flask-WTF使用程序密钥来对CSRF令牌 进行签名,所以我们需要为程序设置密钥:
1 | app.secret_key = 'secret string' |
定义WTForms表单类
当使用WTForms创建表单时,表单由Python类表示,这个类继承从 WTForms导入的Form基类。一个表单由若干个输入字段组成,这些字 段分别用表单类的类属性来表示(字段即Field,你可以简单理解为表单 内的输入框、按钮等部件)。下面定义了一个LoginForm类,最终会生 成我们在前面定义的HTML表单:
1 | from wtforms import Form, StringField, PasswordField, BooleanField, SubmitField |
每个字段属性通过实例化WTForms提供的字段类表示。字段属性的名称将作为对应HTML<input>元素的name属性及id属性值。
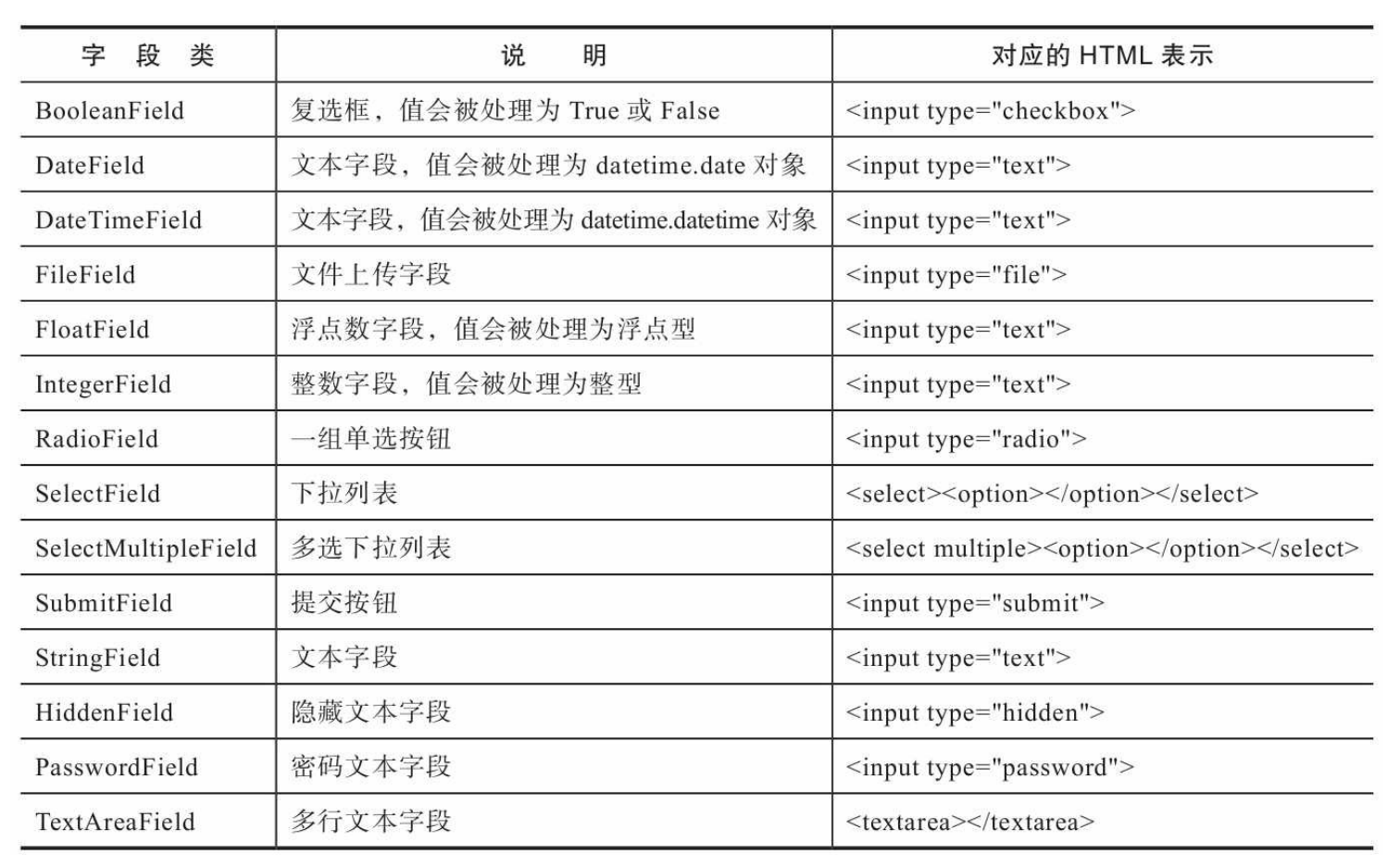

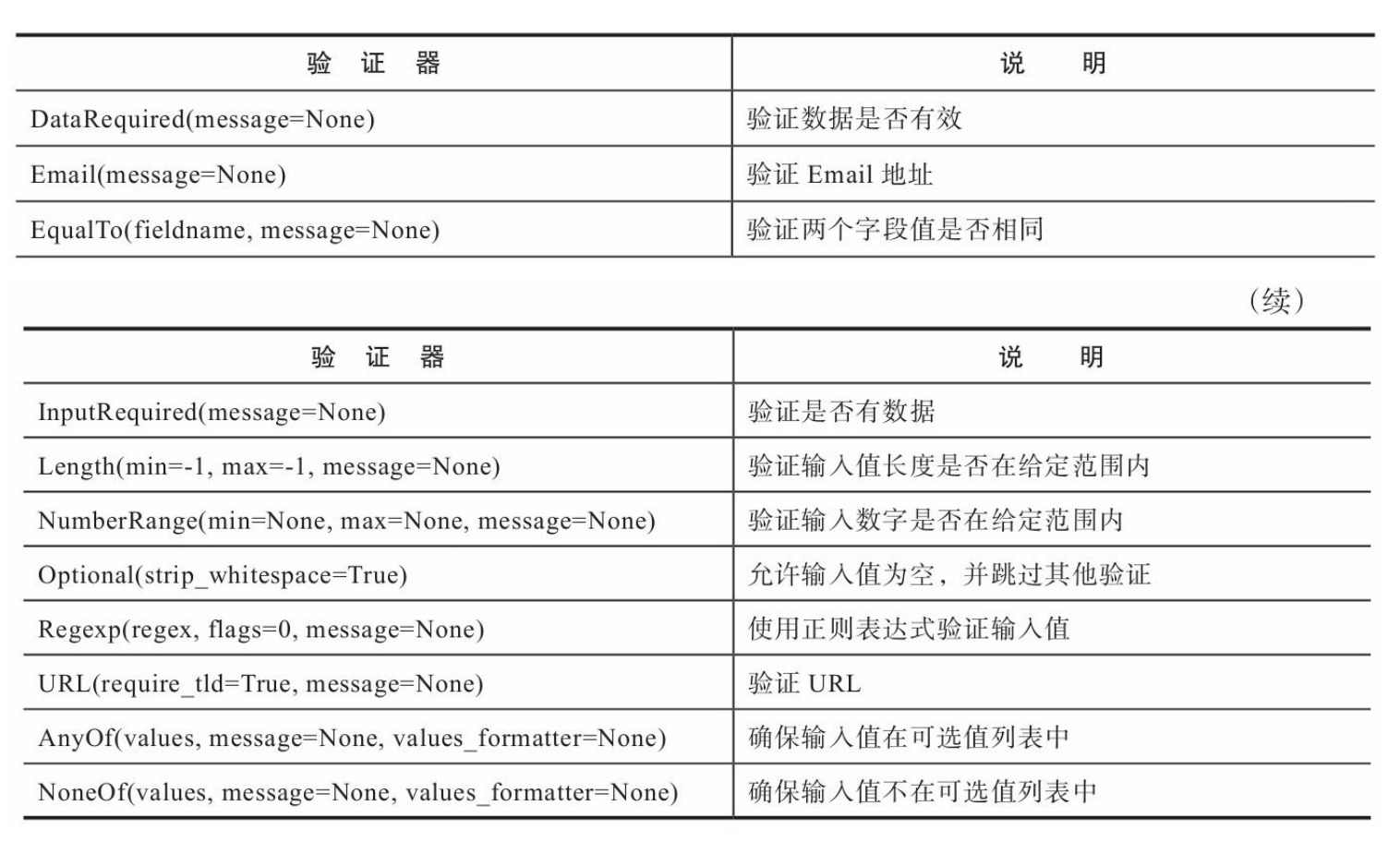
当使用Flask-WTF定义表单时,我们仍然使用WTForms提供的字段类和验证器,创建的方式也完全相同,只不过表单类要继承Flask-WTF提供的FlaskForm类。FlaskForm类继承自Form类,进行了一些设置,并附加了一些辅助方法,以便与Flask集成。
输出HTML代码
以我们使用WTForms创建的LoginForm为例,实例化表单类,然后将实例属性转换成字符串或直接调用就可以获取表单字段对应的HTML代码:
1 | >> form = LoginForm() >>> form.username() |
在创建HTML表单时,我们经常会需要使用HTML<input>元素的其 他属性来对字段进行设置。比如,添加class属性设置对应的CSS类为字段添加样式;添加placeholder属性设置占位文本。默认情况下,WTForms输出的字段HTML代码只会包含id和name属性,属性值均为表单类中对应的字段属性名称。如果要添加额外的属性,通常有两种方法。
- 使用render_kw属性
1 | username = StringField('Username', render_kw={'placeholder': 'Your Username'}) |
1 | <input type="text" id="username" name="username" placeholder="Your Username"> |
- 在调用字段时传入
1 | >> form.username(style='width: 200px;', class_='bar') |
在模板中渲染表单
为了能够在模板中渲染表单,我们需要把表单类实例传入模板。首 先在视图函数里实例化表单类LoginForm,然后在render_template()函 数中使用关键字参数form将表单实例传入模板。
1 | from flask import Flask, render_template, redirect, url_for, flash |
1 | <form method="post"> {{ form.csrf_token }} |
需要注意的是,在上面的代码中,除了渲染各个字段的标签和字段本身,我们还调用了form.csrf_token属性渲染Flask-WTF为表单类自动创建的CSRF令牌字段。form.csrf_token字段包含了自动生成的CSRF令牌值,在提交表单后会自动被验证,为了确保表单通过验证,我们必须在表单中手动渲染这个字段。
处理表单数据
表单数据的处理涉及很多内容,除去表单提交不说,从获取数据到保存数据大致会经历以下步骤:
- 解析请求,获取表单数据。
- 对数据进行必要的转换,比如将勾选框的值转换成Python的布尔值。
- 验证数据是否符合要求,同时验证CSRF令牌。
- 如果验证未通过则需要生成错误消息,并在模板中显示错误消息。
- 如果通过验证,就把数据保存到数据库或做进一步处理。
除非是简单的程序,否则手动处理不太现实,使用Flask-WTF和 WTForms可以极大地简化这些步骤。
提交表单
在HTML中,当<form>标签声明的表单中类型为submit的提交字段被单击时,就会创建一个提交表单的HTTP请求,请求中包含表单各个字段的数据。
表单的提交行为主要由三个属性控制,如下图所示。
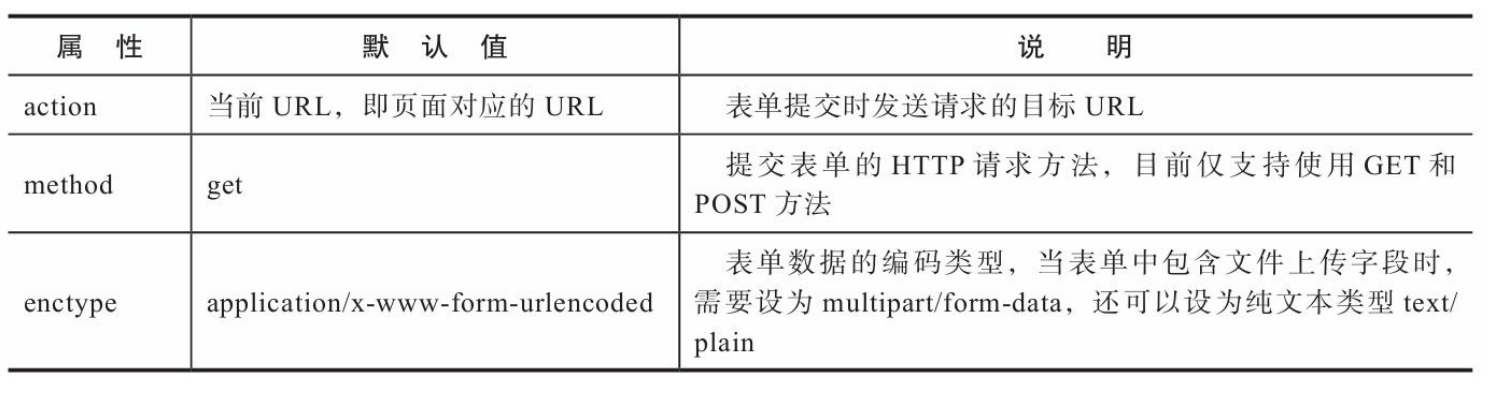
form标签的action属性用来指定表单被提交的目标URL,默认为当前URL,也就是渲染该模板的路由所在的URL。如果你要把表单数据发送到其他URL,可以自定义这个属性值。
验证表单数据
表单数据的验证是Web表单中最重要的主题之一,这一节我们会学习如何使用Flask-WTF验证并获取表单数据。
客户端验证和服务器端验证
表单的验证通常分为以下两种形式:- 客户端验证
客户端验证(client side validation)是指在客户端(比如Web浏览器)对用户的输入值进行验证。比如,使用HTML5内置的验证属性即可实现基本的客户端验证(type、required、min、max、accept等)。比如,下面的username字段添加了required标志:
1
<input type="text" name="username" required>
- 服务器端验证
服务器端验证(server side validation)是指用户把输入的数据提交到服务器端,在服务器端对数据进行验证。如果验证出错,就在返回的响应中加入错误信息。用户修改后再次提交表单,直到通过验证。我们在Flask程序中使用WTForms实现的就是服务器端验证。
- 客户端验证
WTForms验证机制
WTForms验证表单字段的方式是在实例化表单类时传入表单数据,然后对表单实例调用validate()方法。这会逐个对字段调用字段实例化时定义的验证器,返回表示验证结果的布尔值。如果验证失败,就把错误消息存储到表单实例的errors属性对应的字典中,验证的过程如下所示:
1 | >> from wtforms import Form, StringField, PasswordField, BooleanField |
- 在视图函数中验证表单
因为现在的basic_form视图同时接收两种类型的请求:GET请求和POST请求。所以我们要根据请求方法的不同执行不同的代码。具体来说:首先是实例化表单,如果是GET请求,那么就渲染模板;如果是 POST请求,就调用validate()方法验证表单数据。
1 |
|
在模板中渲染错误消息
如果form.validate_on_submit()返回False,那么说明验证没有通 过。对于验证未通过的字段,WTForms会把错误消息添加到表单类的 errors属性中,这是一个匹配作为表单字段的类属性到对应的错误消息 列表的字典。我们一般会直接通过字段名来获取对应字段的错误消息列表,即"form.字段名.errors"。比如,form.name.errors返回name字段的错 误消息列表。
1 | <form method="post"> |
第5章 数据库(重点)
数据库是大多数动态Web程序的基础设施,只要你想把数据存储下来,就离不开数据库。我们这里提及的数据库(Database)指的是由存储数据的单个或多个文件组成的集合,它是一种容器,可以类比为文件柜。而人们通常使用数据库来表示操作数据库的软件,这类管理数据库的软件被称为数据库管理系统(DBMS,Database Management System),常见的DBMS有MySQL、PostgreSQL、SQLite、MongoDB等。为了便于理解,我们可以把数据库看作一个大仓库,仓库里有一些负责搬运货物(数据)的机器人,而DBMS就是操控机器人搬运货物的程序。
数据库的分类
数据库一般分为两种,SQL(Structured Query Language,结构化查 询语言)数据库和NoSQL(Not Only SQL,泛指非关系型)数据库。
SQL
SQL数据库指关系型数据库,常用的SQL DBMS主要包括SQL Server、Oracle、MySQL、PostgreSQL、SQLite等。关系型数据库使用表来定义数据对象,不同的表之间使用关系连接。
在SQL数据库中,每一行代表一条记录(record),每条记录又由不同的列(column)组成。在存储数据前,需要预先定义表模式(schema),以定义表的结构并限定列的输入数据类型。
为了避免在措辞上引起误解,我们先了解几个基本概念:
- 表(table):存储数据的特定结构。
- 模式(schema):定义表的结构信息。
- 列/字段(column/field):表中的列,存储一系列特定的数据,列组成表。
- 行/记录(row/record):表中的行,代表一条记录。
- 标量(scalar):指的是单一数据,与之相对的是集合 (collection)。
NoSQL
NoSQL最初指No SQL或No Relational,现在NoSQL社区一般会解释为Not Only SQL。NoSQL数据库泛指不使用传统关系型数据库中的表格形式的数据库。近年来,NoSQL数据库越来越流行,被大量应用在实时(real-time)Web程序和大型程序中。与传统的SQL数据库相比,它在速度和可扩展性方面有很大的优势,除此之外还拥有无模式(schema- free)、分布式、水平伸缩(horizontally scalable)等特点。
最常用的两种NoSQL数据库如下所示:
- 文档存储(document store)
文档存储是NoSQL数据库中最流行的种类,它可以作为主数据库使用。文档存储使用的文档类似SQL数据库中的记录,文档使用类JSON格式来表示数据。常见的文档存储DBMS有MongoDB、CouchDB等。 - 键值对存储(key-value store)
键值对存储在形态上类似Python中的字典,通过键来存取数据,在读取上非常快,通常用来存储临时内容,作为缓存使用。常见的键值对 DBMS有Redis、Riak等,其中Redis不仅可以管理键值对数据库,还可以作为缓存后端(cache backend)和消息代理(message broker)。
另外,还有列存储(column store,又被称为宽列式存储)、图存储(graph store)等类型的NoSQL数据库,这里不再展开介绍。
ORM魔法
在Web应用里使用原生SQL语句操作数据库主要存在下面两类问题:
- 手动编写SQL语句比较乏味,而且视图函数中加入太多SQL语句会降低代码的易读性。另外还会容易出现安全问题,比如SQL注入。
- 常见的开发模式是在开发时使用简单的SQLite,而在部署时切换 到MySQL等更健壮的DBMS。但是对于不同的DBMS,我们需要使用不同的Python接口库,这让DBMS的切换变得不太容易。
尽管使用ORM可以避免SQL注入问题,但你仍然需要对传入的查询参数进行验证。
另外,在执行原生SQL语句时也要注意避免使用字符串 拼接或字符串格式化的方式传入参数。
使用ORM可以很大程度上解决这些问题。它会自动帮你处理查询 参数的转义,尽可能地避免SQL注入的发生。
另外,它为不同的DBMS提供统一的接口,让切换工作变得非常简单。
ORM扮演翻译的角色,能够将我们的Python语言转换为DBMS能够读懂的SQL指令,让我们能 够使用Python来操控数据库。
尽管ORM非常方便,但如果你对SQL相当熟悉,那么自己编写SQL代码可以获得更大的灵活性和性能优势。
就像是使用IDE一样,ORM对初学者来说非常方便,但进阶以后你也许会想要自己掌控一切。
ORM把底层的SQL数据实体转化成高层的Python对象,这样一来, 你甚至不需要了解SQL,只需要通过Python代码即可完成数据库操作,ORM主要实现了三层映射关系:
- 表→Python类。
- 字段(列)→类属性。
- 记录(行)→类实例。
比如,我们要创建一个contacts表来存储留言,其中包含用户名称和电话号码两个字段。
在SQL中,下面的代码用来创建这个表,要向表中插入一条记录,需要使用下面的SQL语句:
1 | CREATE TABLE contacts( |
如果使用ORM,我们可以使用类似下面的Python类来定义这个表:
使用ORM则只需要创建一个Contact类的实例,传入对应的参数表示各个列的数据即可。
下面的代码和使用上面的SQL语句效果相同:
1 | from foo_orm import Model, Column, String |
除了便于使用,ORM还有下面这些优点:
- 灵活性好。你既能使用高层对象来操作数据库,又支持执行原生 SQL语句。
- 提升效率。从高层对象转换成原生SQL会牺牲一些性能,但这微不足道的性能牺牲换取的是巨大的效率提升。
- 可移植性好。ORM通常支持多种DBMS,包括MySQL、PostgreSQL、Oracle、SQLite等。你可以随意更换DBMS,只需要稍微 改动少量配置。
使用Python实现的ORM有SQLAlchemy、Peewee、PonyORM等。其中SQLAlchemy是Python社区使用最广泛的ORM之一,我们将介绍如何在Flask程序中使用它。SQL-Alchemy,直译过来就是SQL炼金术,下一节我们会见识到SQLAlchemy的神奇力量。
使用Flask-SQLAlchemy管理数据库
扩展Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器、管理数据库操作会话等各类工作,让Flask中的数据处理体验变得更加轻松。
下面在示例程序中实例化Flask-SQLAlchemy提供的SQLAlchemy类,传入程序实例app,以完成扩展的初始化。
1 | import os |
连接数据库服务器
DBMS通常会提供数据库服务器运行在操作系统中。要连接数据库服务器,首先要为我们的程序指定数据库URI(Uniform Resource
Identifier,统一资源标识符)。数据库URI是一串包含各种属性的字符串,其中包含了各种用于连接数据库的信息。

在Flask-SQLAlchemy中,数据库的URI通过配置变量SQLALCHEMY_DATABASE_URI设置,默认为SQLite内存型数据库(sqlite:///:memory:)。SQLite是基于文件的DBMS,不需要设置数据库服务器,只需要指定数据库文件的绝对路径。
在生产环境下更换到其他类型的DBMS时,数据库URL会包含敏感 信息,所以这里优先从环境变量DATABASE_URL获取(注意这里为了便于理解使用了URL,而不是URI)。
安装并初始化Flask-SQLAlchemy后,启动程序时会看到命令行下有一行警告信息。这是因为Flask-SQLAlchemy建议你设置 SQLALCHEMY_TRACK_MODIFICATIONS配置变量,这个配置变量决定是否追踪对象的修改,这用于Flask-SQLAlchemy的事件通知系统。这 个配置键的默认值为None,如果没有特殊需要,我们可以把它设为False来关闭警告信息。
1 | app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False |
定义数据库模型
用来映射到数据库表的Python类通常被称为数据库模型
(model),一个数据库模型类对应数据库中的一个表。定义模型即使用Python类定义表模式,并声明映射关系。所有的模型类都需要继承Flask-SQLAlchemy提供的db.Model基类。本章的示例程序是一个笔记程序,笔记保存到数据库中,你可以通过程序查询、添加、更新和删除笔记。
1 | class Note(db.Model): |
在上面的模型类中,表的字段(列)由db.Column类的实例表示,字段的类型通过Column类构造方法的第一个参数传入。在这个模型中,我们创建了一个类型为db.Integer的id字段和类型为db.Text的body列,分别存储整型和文本。
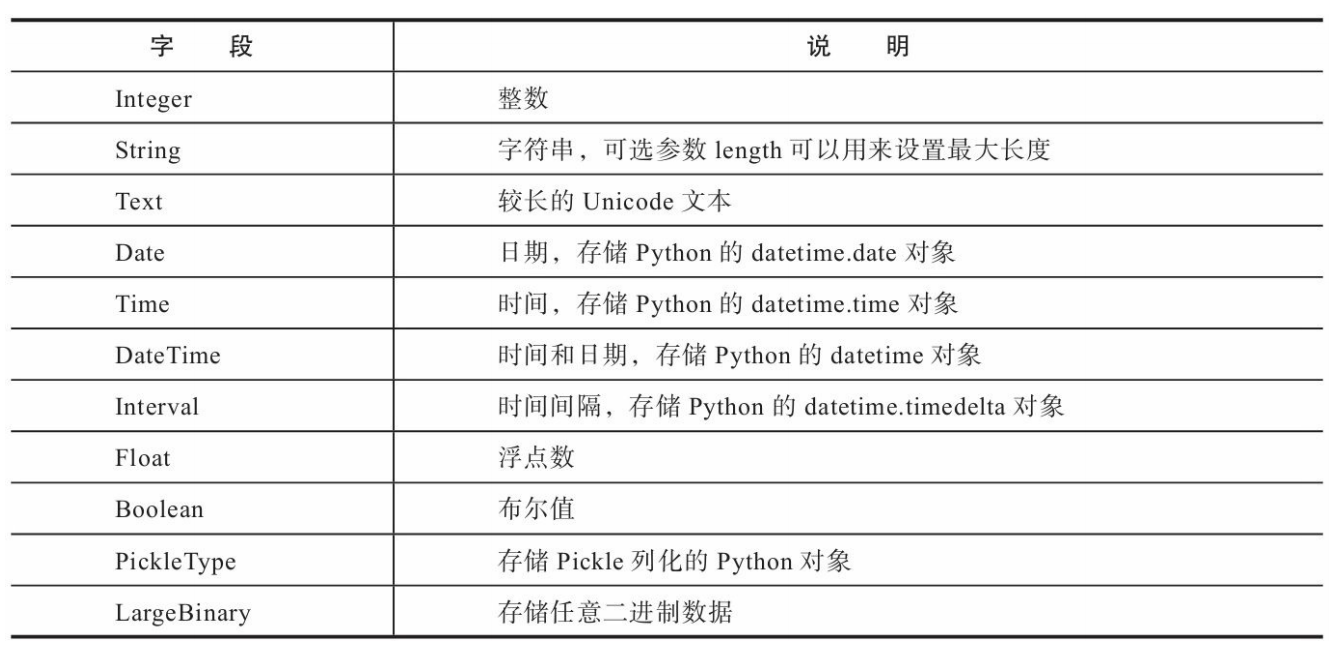
字段类型一般直接声明即可,如果需要传入参数,你也可以添加括号。对于类似String的字符串列,有些数据库会要求限定长度,因此最 好为其指定长度。虽然使用Text类型可以存储相对灵活的变长文本,但从性能上考虑,我们仅在必须的情况下使用Text类型,比如用户发表的文章和评论等不限长度的内容。
一般情况下,字段的长度是由程序设计者自定的。尽管如此,也有一些既定的约束标准,比如姓名(英语)的长度一般不超过70个字符,中文名一般不超过20个字符,电子邮件地址的长度不超过254个字符,虽然各主流浏览器支持长达2048个字符的URL,但在网站中用户资料设置的限度一般为255。尽管如此,对于超过一定长度的Email和URL,比如20个字符,会在显示时添加省略号的形式。显示的用户名(username)允许重复,通常要短一些,以不超过36个字符为佳。当然,在程序中,你可以根据需要来自由设定这些限制值。
创建数据库和表
如果把数据库(文件)看作一个仓库,为了方便取用,我们需要把货物按照类型分别放置在不同货架上,这些货架就是数据库中的表。创建模型类后,我们需要手动创建数据库和对应的表,也就是我们常说的建库和建表。这通过对我们的db对象调用create_all()方法实现。
数据库操作
现在我们创建了模型,也生成了数据库和表,是时候来学习常用的数据库操作了。数据库操作主要是CRUD,即Create(创建)、Read(读取/查询)、Update(更新)和Delete(删除)。SQLAlchemy使用数据库会话来管理数据库操作,这里的数据库会话也称为事务(transaction)。Flask-SQLAlchemy自动帮我们创建会话,可以通过db.session属性获取。
数据库中的会话代表一个临时存储区,你对数据库做出的改动都会存放在这里。你可以调用add()方法将新创建的对象添加到数据库会话中,或是对会话中的对象进行更新。只有当你对数据库会话对象调用commit()方法时,改动才被提交到数据库,这确保了数据提交的一致性。另外,数据库会话也支持回滚操作。当你对会话调用rollback()方法时,添加到会话中且未提交的改动都将被撤销。
CRUD
这一节我们会在Python Shell中演示CRUD操作。默认情况下,Flask-SQLAlchemy(>=2.3.0版本)会自动为模型类生成一个__repr__()方法。当在Python Shell中调用模型的对象时,__repr__()方法会返回一条类似“<模型类名主键值>”的字符串,比如<Note>。
Create
添加一条新记录到数据库主要分为三步:- 创建Python对象(实例化模型类)作为一条记录。
- 添加新创建的记录到数据库会话。
- 提交数据库会话。
Read
我们已经知道了如何向数据库里添加记录,那么如何从数据库里取回数据呢?使用模型类提供的query属性附加调用各种过滤方法及查询方法可以完成这个任务。
1 | <模型类>.query.<过滤方法>.<查询方法> |
从某个模型类出发,通过在query属性对应的Query对象上附加的过滤方法和查询函数对模型类对应的表中的记录进行各种筛选和调整,最终返回包含对应数据库记录数据的模型类实例,对返回的实例调用属性即可获取对应的字段数据。
精确的查询,比如获取指定字段值的记录。对模型类的query属性存储的Query对象调用过滤方法将返回一个更精确的Query对象(后面我们简称为查询对象)。因为每个过滤方法都会返回新的查询对象,所以过滤器可以叠加使用。在查询对象上调用前面介绍的查询方法,即可获得一个包含过滤后的记录的列表。

Update
更新一条记录非常简单,直接赋值给模型类的字段属性就可以改变 字段值,然后调用commit()方法提交会话即可。
只有要插入新的记录或要将现有的记录添加到会话中时才需要使用 add()方法,单纯要更新现有的记录时只需要直接为属性赋新值,然 后提交会话。Delete
删除记录和添加记录很相似,不过要把add()方法换成delete() 方法,最后都需要调用commit()方法提交修改。
在视图函数里操作数据库
在视图函数里操作数据库的方式和我们在Python Shell中的练习大致相同,只不过需要一些额外的工作。比如把查询结果作为参数传入模板渲染出来,或是获取表单的字段值作为提交到数据库的数据。在这一节,我们将把上一节学习的所有数据库操作知识运用到一个简单的笔记程序中。这个程序可以让你创建、编辑和删除笔记,并在主页列出所有保存后的笔记。
- Create
1 |
|
- Read
1 |
|
- Update
1 |
|
- Delete
1 |
|
定义关系
在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系。一般来说,定义关系需要两步,分别是创建外键和定义关系属性。在更复杂的多对多关系中,我们还需要定义关联表来管理关系。这一节我们会学习如何使用SQLAlchemy在模型之间建立几种基础的关系模 式。
配置Python Shell上下文
在上面的许多操作中,每一次使用flask shell命令启动Python Shell后都要从app模块里导入db对象和相应的模型类。为什么不把它们自动 集成到Python Shell上下文里呢?就像Flask内置的app对象一样。这当然可以实现!我们可以使用app.shell_context_processor装饰器注册一个shell上下文处理函数。
1 | # handlers |
一对多
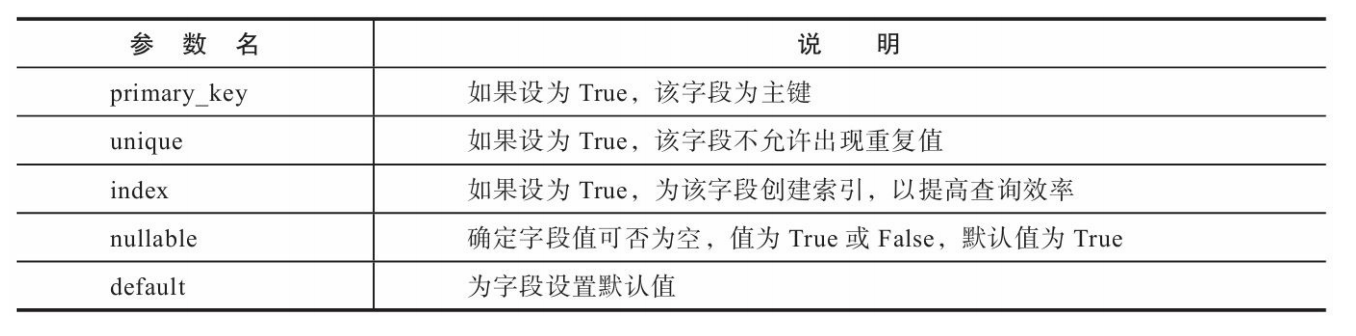
我们将以作者和文章来演示一对多关系:一个作者可以写作多篇文章。
Author类用来表示作者,Article类用来表示文章
1 | class Author(db.Model): |
我们将在这两个模型之间建立一个简单的一对多关系,建立这个一对多关系的目的是在表示作者的Author类中添加一个关系属性articles,
作为集合(collection)属性,当我们对特定的Author对象调用articles属性会返回所有相关的Article对象。我们会在下面介绍如何一步步定义这个一对多关系。
定义外键
定义关系的第一步是创建外键。外键是(foreign key)用来在A表存储B表的主键值以便和B表建立联系的关系字段。因为外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义,多篇文章属于同一个作者,所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。在Article模型中,我们定义一个author_id字段作为外键.定义关系属性
定义关系的第二步是使用关系函数定义关系属性。关系属性在关系 的出发侧定义,即一对多关系的“一”这一侧。一个作者拥有多篇文章, 在Author模型中,我们定义了一个articles属性来表示对应的多篇文章建立关系
建立关系有两种方式,第一种方式是为外键字段赋值,另一种方式是通过操作关系属性,将关系属性赋给实际的对象即可建立关系。
1 | # 1.外键字段赋值 |


- 建立双向关系
我们在Author类中定义了集合关系属性articles,用来获取某个作者 拥有的多篇文章记录。在某些情况下,你也许希望能在Article类中定义 一个类似的author关系属性,当被调用时返回对应的作者记录,这类返 回单个值的关系属性被称为标量关系属性。而这种两侧都添加关系属性 获取对方记录的关系我们称之为双向关系(bidirectional relationship)。
双向关系并不是必须的,但在某些情况下会非常方便。双向关系的 建立很简单,通过在关系的另一侧也创建一个relationship()函数,我 们就可以在两个表之间建立双向关系。
1 | # one to many + bidirectional relationship |
- 使用backref简化关系定义
在介绍关系函数的参数时,我们曾提到过,使用关系函数中的 backref参数可以简化双向关系的定义。以一对多关系为例,backref参数
用来自动为关系另一侧添加关系属性,作为反向引用(back reference),赋予的值会作为关系另一侧的关系属性名称。比如,我们 在Author一侧的关系函数中将backref参数设为author,SQLAlchemy会自 动为Article类添加一个author属性。
1 | # 尽管使用backref非常方便,但通常来说“显式好过隐式”,所以我们 应该尽量使用back_populates定义双向关系。 |
在定义集合属性songs的关系函数中,我们将backref参数设为 singer,这会同时在Song类中添加了一个singer标量属性。这时我们仅需 要定义一个关系函数,虽然singer是一个“看不见的关系属性”,但在使用上和定义两个关系函数并使用back_populates参数的效果完全相同。需要注意的是,使用backref允许我们仅在关系一侧定义另一侧的关 系属性,但是在某些情况下,我们希望可以对在关系另一侧的关系属性进行设置,这时就需要使用backref()函数。backref()函数接收第一 个参数作为在关系另一侧添加的关系属性名,其他关键字参数会作为关 系另一侧关系函数的参数传入。比如,我们要在关系另一侧“看不见的 relationship()函数”中将uselist参数设为False。
多对一
一对多关系反过来就是多对一关系,这两种关系模式分别从不同的视角出发。一个作者拥有多篇文章,反过来就是多篇文章属于同一个作者。为了便于区分,我们使用居民和城市来演示多对一关系:多个居民居住在同一个城市。
1 | # many to one |
这时定义的city关系属性是一个标量属性(返回单一数据)。当Citizen.city被调用时,SQLAlchemy会根据外键字段city_id存储的值查找对应的City对象并返回,即居民记录对应的城市记录。
当建立双向关系时,如果不使用backref,那么一对多和多对一关系模式在定义上完全相同,这时可以将一对多和多对一视为同一种关系模式。在后面我们通常都会为一对多或多对一建立双向关系,这时将弱化这两种关系的区别,一律称为一对多关系。
一对一
我们将使用国家和首都来演示一对一关系:每个国家只有一个首 都;反过来说,一个城市也只能作为一个国家的首都。
Country类表示国家,Capital类表示首都。建立一对一关系后,我们将在Country类中创建一个标量关系属性capital,调用它会获取单个Capital对象;我们还将在Capital类中创建一个标量关系属性country,调用它会获取单个的Country对象。
一对一关系实际上是通过建立双向关系的一对多关系的基础上转化而来。我们要确保关系两侧的关系属性都是标量属性,都只返回单个值,所以要在定义集合属性的关系函数中将uselist参数设为False,这时一对多关系将被转换为一对一关系。
1 | # one to one |
多对多
我们将使用学生和老师来演示多对多关系:每个学生有多个老师,而每个老师有多个学生。
Student类表示学生,Teacher类表示老师。在这两个模型之间建立多对多关系后,我们需要在Student类中添加一个集合关系属性teachers,调用它可以获取某个学生的多个老师,而不同的学生可以和同一个老师建立关系。
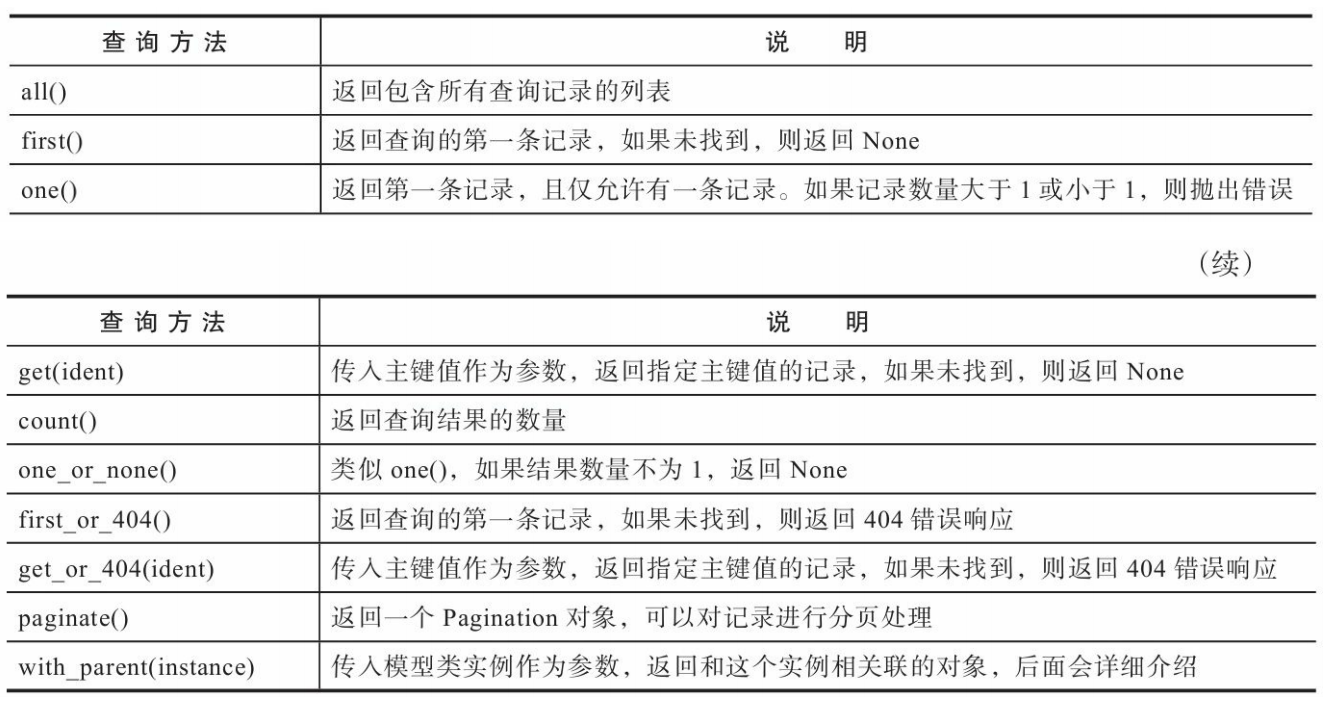
在一对多关系中,我们可以在“多”这一侧添加外键指向“一”这一 侧,外键只能存储一个记录,但是在多对多关系中,每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。在SQLAlchemy中,要想表示多对多关系,除了关系两侧的模型外,我们还需要创建一个关联表(association table)。关联表不存储数据,只用来存储关系两侧模型的外键对应关系。
1 | class Student(db.Model): |
关联表使用db.Table类定义,传入的第一个参数是关联表的名称。我们在关联表中定义了两个外键字段:teacher_id字段存储Teacher类的主键,student_id存储Student类的主键。借助关联表这个中间人存储的外键对,我们可以把多对多关系分化成两个一对多关系,如图所示。
更新数据库表
模型类(表)不是一成不变的,当你添加了新的模型类,或是在模 型类中添加了新的字段,甚至是修改了字段的名称或类型,都需要更新 表。在前面我们把数据库表类比成盛放货物的货架,这些货架是固定生 成的。当我们在操控程序(DBMS/ORM)上变更了货架的结构时,仓 库的货架也要根据变化相应进行调整。而且,当货架的结构产生变动 时,我们还需要考虑如何处理货架上的货物(数据)。
重新生成表
重新调用create_all()方法并不会起到更新表或重新创建表的作 用。如果你并不在意表中的数据,最简单的方法是使用drop_all()方法删除表以及其中的数据,然后再使用create_all()方法重新创建
使用Flask-Migrate迁移数据库
在开发时,以删除表再重建的方式更新数据库简单直接,但明显的缺陷是会丢掉数据库中的所有数据。在生产环境下,你绝对不会想让数 据库里的数据都被删除掉,这时你需要使用数据库迁移工具来完成这个工作。
SQLAlchemy的开发者Michael Bayer写了一个数据库迁移工具 ——Alembic来帮助我们实现数据库的迁移,数据库迁移工具可以在不破坏数据的情况下更新数据库表的结构。蒸馏器(Alembic)是炼金术士最重要的工具,要学习SQL炼金术(SQLAlchemy),我们当然要掌 握蒸馏器的使用。
我们实例化Flask-Migrate提供的Migrate类,进行初始化操作
实例化Migrate类时,除了传入程序实例app,还需要传入实例化 Flask-SQLAlchemy提供的SQLAlchemy类创建的db对象作为第二个参数。
1 | from flask import Flask from flask_sqlalchemy |
- 创建迁移环境
在开始迁移数据之前,需要先使用下面的命令创建一个迁移环境
迁移环境只需要创建一次。这会在你的项目根目录下创建一个migrations文件夹,其中包含了自动生成的配置文件和迁移版本文件夹。
1 | flask db init |
- 生成迁移脚本
使用migrate子命令可以自动生成迁移脚本:
1 | flask db migrate -m "add note timestamp" |
这条命令可以简单理解为在flask里对数据库(db)进行迁移 (migrate)。-m选项用来添加迁移备注信息。从上面的输出信息我们可以看到,Alembic检测出了模型的变化:表note新添加了一个timestamp列,并且相应生成了一个迁移脚本 c52a02014635_add_note_timestamp.py,
- 更新数据库
生成了迁移脚本后,使用upgrade子命令即可更新数据库
1 | flask db upgrade |
如果还没有创建数据库和表,这个命令会自动创建;如果已经创建,则会在不损坏数据的前提下执行更新。
开发时是否需要迁移
在生产环境下,当对数据库结构进行修改后,进行数据库迁移是必要的。因为你不想损坏任何数据,毕竟数据是无价的。在生成自动迁移脚本后,执行更新之前,对迁移脚本进行检查,甚至是使用备份的数据库进行迁移测试,都是有必要的。
而在开发环境中,你可以按需要选择是否进行数据迁移。对于大多数程序来说,我们可以在开发时使用虚拟数据生成工具来生成虚拟数据,从而避免手动创建记录进行测试。这样每次更改表结构时,可以直接清除后重新生成,然后生成测试数据,这要比执行一次迁移简单很多(在后面我们甚至会学习通过一条命令完成所有工作),除非生成虚拟数据耗费的时间过长。
另外,在本地开发时通常使用SQLite作为数据库引擎。SQLite不支持ALTER语句,而这正是迁移工具依赖的工作机制。也就是说,当SQLite数据库表的字段删除或修改后,我们没法直接使用迁移工具进行更新,你需要手动添加迁移代码来进行迁移。在开发中,修改和删除列是很常见的行为,手动操作迁移会花费太多的时间。
总结
本来还有一章讲邮件的,但是邮件这部分太简单就不放在这里了。
基础篇(二)主要是讲数据库的知识,简单了解在Flask应用中使用数据库的方法,但数据库的内容还有很多,这里只是一个简单的介绍。
如果你想了解更多具体细节,SQLAlchemy提供的入门教程是个起步的好地方。
另外,如果还不熟悉SQL,那么有必要去学习一下,掌握SQL可以让你更高效地使用ORM。
这里也没有介绍在Flask中使用文档型NoSQL数据库的过程。
以流行的MongoDB为例,通过使用ODM(Object Document Mapper,对象文档映射),比如MongoEngine,或是对应的扩展Flask- MongoEngine,其操作数据库的方式和使用本章要介绍的SQLAlchemy基本相同。




