最近我把 OpenCode 当成主力 coding agent 在用。网上已经有不少“功能总览”文章,但很多内容像产品说明书:信息全,落地弱。
这篇我按“真实开发流程”重写一版,重点是:你今天装好后,怎么在项目里稳定产出,而不是只会敲 /help。
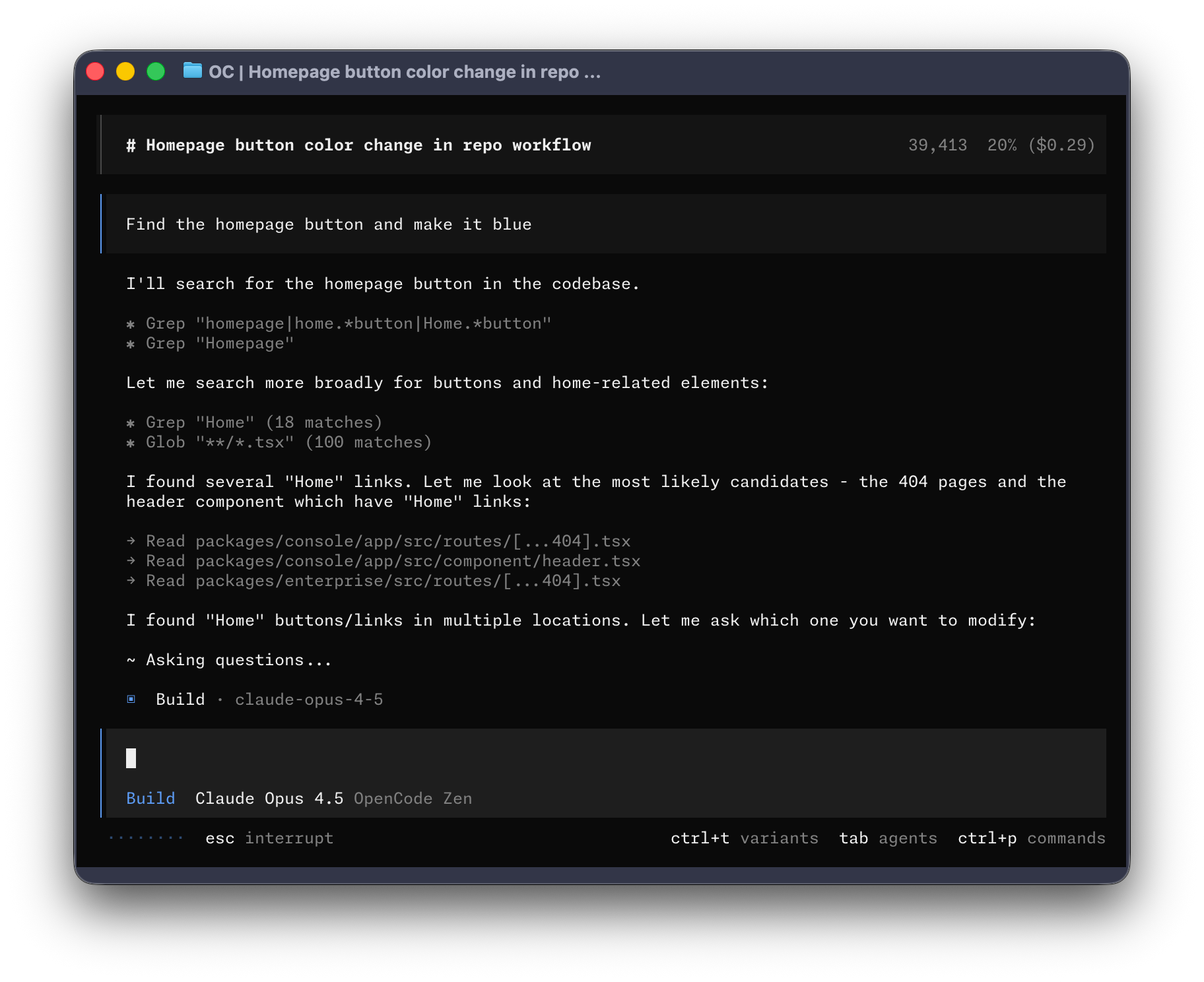
图源:OpenCode 官方文档 Intro 页
一、先讲结论:OpenCode 适合什么人
如果你符合下面 3 条中的 2 条,OpenCode 会比“IDE 内嵌 AI 聊天框”更好用:
- 你愿意在终端里工作,接受命令行思维。
- 你希望 agent 不止回答问题,还能“读写文件 + 跑命令 + 调外部工具”。
- 你在意可控性(权限、规则、可审计、可自动化),而不是“一键魔法”。
简单理解:
- Cursor/Copilot 更像“编辑器里增强写代码”。
- OpenCode 更像“可编排的工程代理平台”。
二、安装与启动:3 分钟跑起来
官方安装方式很多,这里只保留常用命令。
1 | # 一键安装 |
启动方式:
1 | # 在当前目录启动 TUI |
第一次进入建议按这个顺序:
/connect配 provider。/models选模型。/init让它生成项目AGENTS.md。
/init 非常关键,它决定 agent 在你的仓库里是不是“懂规矩”。
三、你每天最常用的 6 个能力(带场景)
1) @文件:把上下文喂准
1 | 解释一下 @src/api/auth.ts 的刷新 token 流程 |
它会把文件内容注入上下文,避免 agent 在大仓库里“猜”。
2) !命令:把终端输出直接回填
1 | !git status |
适合把“报错现场”直接给 agent,不需要复制粘贴。
3) /undo + /redo:可逆编辑
OpenCode 的撤销/重做依赖 Git(仓库必须是 git repo)。
/undo:撤回最后一次消息及其文件修改。/redo:恢复撤销的内容。
这个是我敢让 agent 改代码的底气之一。
4) /compact:上下文太长时续命
长会话一定会碰到 token 压力。/compact 可以保留关键状态,压掉无关历史。
5) /details:审计工具调用
你怀疑 agent 为什么做出某个修改时,打开 /details 看它调了哪些工具、传了什么参数。
6) /editor:写长 prompt 时救命
复杂任务建议进外部编辑器写需求(尤其是带验收标准时)。
1 | export EDITOR="code --wait" |
四、从“会用”到“好用”的关键:Plan -> Build
很多人一上来就让 agent 直接改,结果是:能改,但经常改偏。
更稳的流程:
- 用
plan模式先产方案(默认对 edit/bash 更谨慎)。 - 人工确认边界、风险点。
- 切回
build模式执行。
你可以把它想成:
plan= 资深同事做方案评审。build= 开工落地并提交可运行结果。
一个实用 prompt:
1 | 先不要改代码。先给我: |
五、CLI 子命令怎么选(不是每次都开 TUI)
适合人机协作:TUI
1 | opencode |
适合自动化脚本:run
1 | opencode run "review latest changes and suggest improvements" |
适合服务化:serve / web
1 | opencode serve |
适合远程附着:attach
1 | opencode attach http://127.0.0.1:4096 |
适合 MCP 管理:opencode mcp ...
1 | opencode mcp add |
适合会话与成本复盘
1 | opencode session list |
六、权限系统:让 agent “能干活但不乱来”
权限只有三种动作:
allow:直接执行ask:执行前确认deny:拒绝
推荐起步策略:高风险工具 ask,低风险默认 allow。
1 | { |
两个容易被忽略的点:
- 规则是“最后匹配生效”(last match wins)。
external_directory和doom_loop是额外安全阀,默认建议保留ask。
七、MCP 才是 OpenCode 的上限(结合你的组合)
你现在这组 context7 + gh_grep + exa 很实用,我建议按“信息可靠性分层”用:
- 官方定义先走
context7。 - 真实代码范式走
gh_grep。 - 时效信息补充走
exa。
一个可直接用的 MCP 配置示例
1 | { |
如果你要启用 Exa Web Search(按官方说明):
1 | OPENCODE_ENABLE_EXA=1 opencode |
八、把“低幻觉”流程写进提示词
你原文里这个思路非常对,我给你扩展成可复用模板。
1 | 请按以下顺序回答: |
这样做的好处是:
- 你能看见“依据链”,不是只看结论。
- 讨论能落到“可执行步骤”,不是空话。
九、Rules:为什么 AGENTS.md 值得认真写
OpenCode 会读项目规则文件。你把规则写清楚,等于在降低返工率。
建议 AGENTS.md 至少包含:
- 构建/测试命令(尤其单测命令)。
- 目录边界(哪些文件夹可改,哪些只读)。
- 代码风格和命名规范。
- 提交与验证标准。
在团队里,AGENTS.md 其实就是“给 agent 的 CONTRIBUTING.md”。
十、分享与安全:能分享,但默认要克制
/share 很方便做协作复盘,但要注意链接是公开可访问。
建议默认:
1 | { |
涉敏项目直接:
1 | { |
另外,跑 serve / web 时建议加基本鉴权:
1 | export OPENCODE_SERVER_PASSWORD="your-strong-password" |
十一、一个我自己更推荐的 opencode.json 起步模板
下面这份配置偏“日常开发安全默认 + MCP 增强”。
1 | { |
你可以再按项目微调,比如把 npm test* 放开,或者把某些目录的 edit 设为 deny。
十二、一个完整任务示例(端到端)
目标:给博客项目加“文章字数统计”并验证部署。
建议流程:
plan模式描述需求和约束。- 明确“只改
source/与 root config,不改主题子模块”。 build模式执行修改。- 跑
npm run build验证。 - 人工抽查页面。
- 最后再
npm run deploy。
对应 prompt(可直接改后复用):
1 | 先进入 plan 模式,不要改代码。 |
十三、常见坑(我自己踩过)
- 没写规则就开干:结果是 agent 改了你不想改的目录。
- 权限全 allow:短期爽,长期会有不可控风险。
- MCP 开太多:上下文被工具说明吃掉,反而变慢变贵。
- 不做会话压缩:长会话后期质量明显下降。
- 只要答案,不要依据:最后很难判断对错,只能“凭感觉相信”。
十四、最后的使用建议(针对你这种重度用户)
如果你已经在稳定使用 OpenCode,我建议把目标从“会用命令”升级到“可复制的工作流”:
- 固化
AGENTS.md(项目规则)。 - 固化
opencode.json(权限与模型策略)。 - 固化提问模板(context7 -> gh_grep -> exa)。
- 固化验收步骤(build/test/lint/手工检查)。
当这 4 件事稳定后,OpenCode 就不只是“AI 助手”,而是你工程流程的一部分。
参考资料(官方)
- Intro: https://opencode.ai/docs/
- TUI: https://opencode.ai/docs/tui/
- CLI: https://opencode.ai/docs/cli/
- Config: https://opencode.ai/docs/config/
- Tools: https://opencode.ai/docs/tools/
- Permissions: https://opencode.ai/docs/permissions/
- Agents: https://opencode.ai/docs/agents/
- Commands: https://opencode.ai/docs/commands/
- MCP Servers: https://opencode.ai/docs/mcp-servers/




